Chapter 7 Time series regression models
# loading libraries
library(tsibble)
library(tsibbledata)
library(tidyverse)
# to read data
library(rio)
library(ggplot2)
library(fabletools)
library(feasts)
library(fpp3)
library(latex2exp)
library(forecast)The basic concept is that we forecast the time series of interest \(y\) assuming that it has a linear relationship with other time series \(x\).
The forecast variable \(y\) is dependent variable, regressand or explained variable. The predictor variables \(x\) are independent variable, regressors or exploratory variable.
7.1 The linear model
7.1.1 Simple linear regression
\[ y_t = \beta_0 + \beta_1x_{1,t} + \varepsilon_t \]
The intercept \(\beta_0\) represents the predicted value of \(y\) when \(x=0\). The slope \(\beta_1\) represents the average predicted change in \(y\) resulting from a one unit increase in \(x\).
\(\varepsilon_t\) or “error” represents a deviation from the underlying straight line model.
7.1.1.1 Example: US consumption expenditure
us_change |>
pivot_longer(cols = c(Consumption, Income), names_to = 'Series') |>
autoplot(value) +
labs(y = '% change')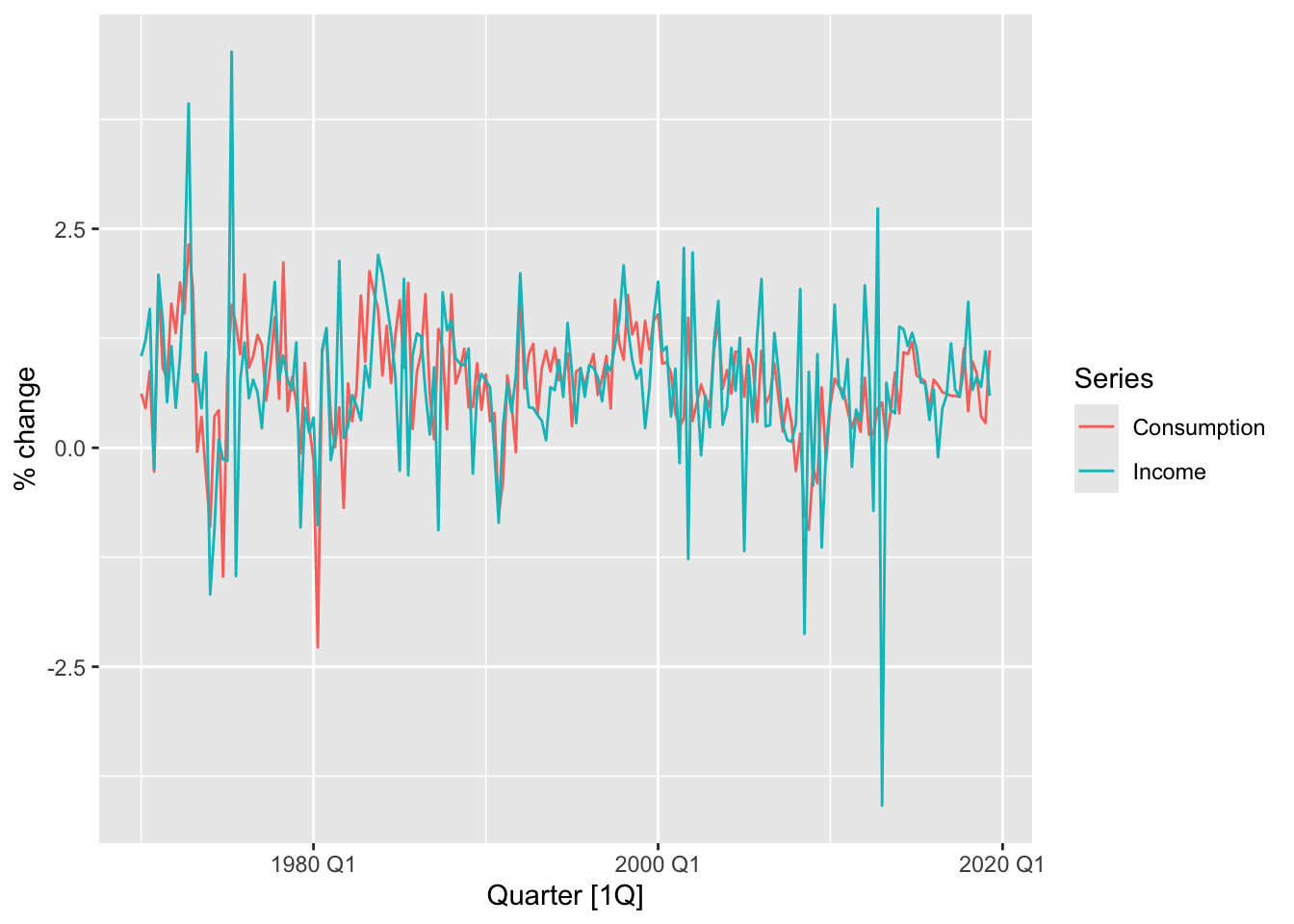
## Series: Consumption
## Model: TSLM
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.58236 -0.27777 0.01862 0.32330 1.42229
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.54454 0.05403 10.079 < 2e-16 ***
## Income 0.27183 0.04673 5.817 2.4e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5905 on 196 degrees of freedom
## Multiple R-squared: 0.1472, Adjusted R-squared: 0.1429
## F-statistic: 33.84 on 1 and 196 DF, p-value: 2.4022e-08\[ \hat y_t = 0.54 + 0.27x_t \]
us_change |>
ggplot(aes(x = Income, y = Consumption)) +
labs(x = 'Income (quarterly % change)',
y = 'Consumption (quarterly % change)') +
geom_point() +
geom_smooth(method = 'lm', se = F)## `geom_smooth()` using formula = 'y ~ x'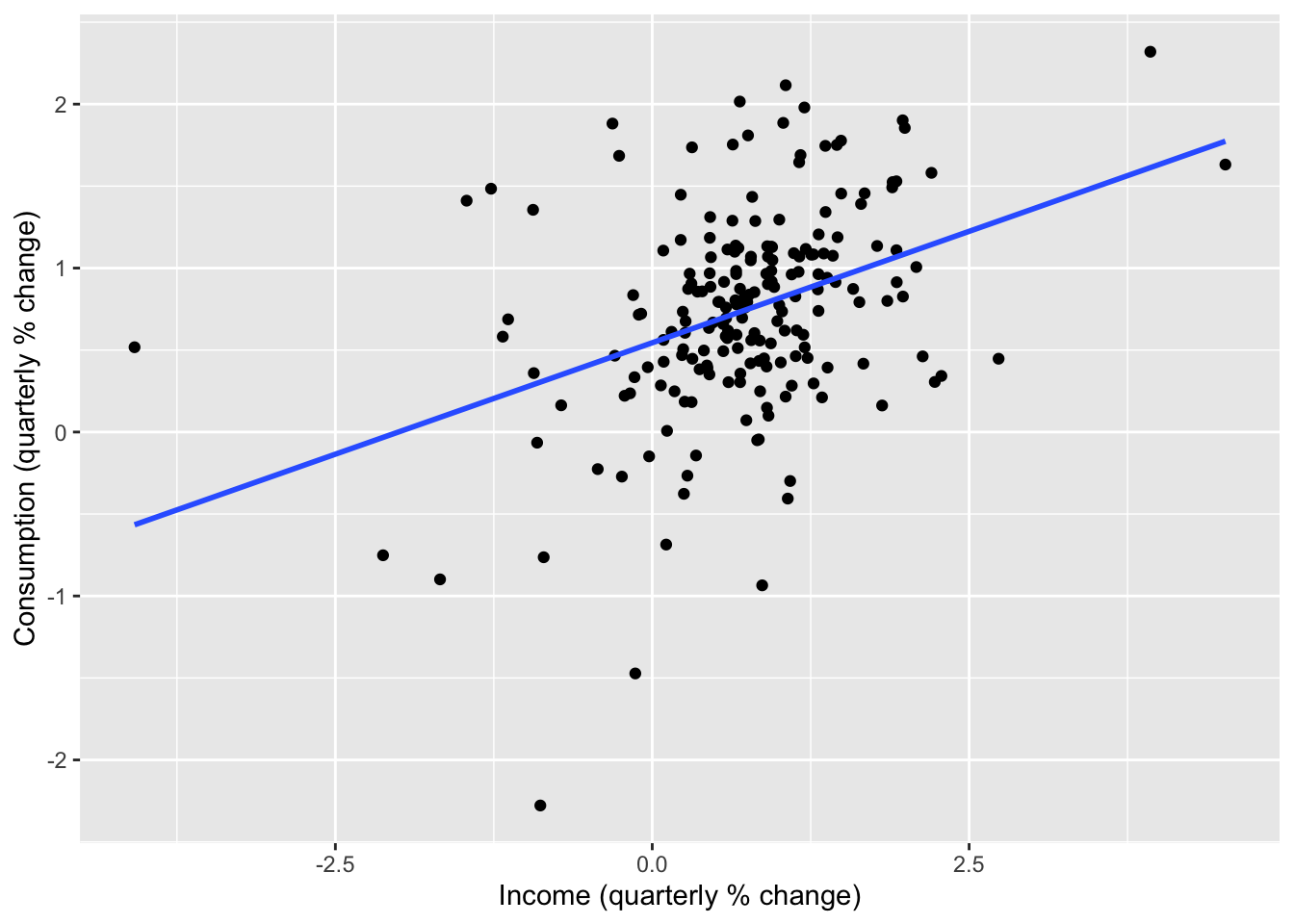
7.1.2 Multiple linear regression
\[ y_t = \beta_0 + \beta_1x_{1,t} + \beta_2x_{2,t} + ... + \beta_kx_{k,t} + \varepsilon_t \]
- \(y_t\) is the variable we want to predict: the “response” variable
- Each \(x_{j,t}\) is numerical and called a “predictor”. They are usually assumed to be known for all past and future times.
- The coefficients \(\beta_1, ..., \beta_k\) measure the effect of each predictor after taking account of the all other predictors in the model.
- \(\varepsilon_t\) is a white noise error term
7.1.3 Assumptions
- The model is a reasonable approximation to reality, the relationship between the forecast variable and the predictor variables satisfies this linear equation.
- \(\varepsilon_t\) have mean zero and are uncorrelated.
- \(\varepsilon_t\) are uncorrelated with aech \(x_{j,t}\).
- Errors are normally distributed with constant variance \(\sigma^2\) in order to easily produce prediction intervals.
7.2 Least squares estimation
The least squares principle provides a way of choosing the coefficients effectively by minimising the sum of the squared errors.
\[ \sum_{t=1}^T \varepsilon_t^2 = \sum_{t=1}^T (y_t - \beta_0 - \beta_1x_{1,t} - \beta_2x_{2,t}-...-- \beta_kx_{k,t})^2 \]
Finding the best estimates of the coefficients is colled fitting the model to the data, or learning or training the model.
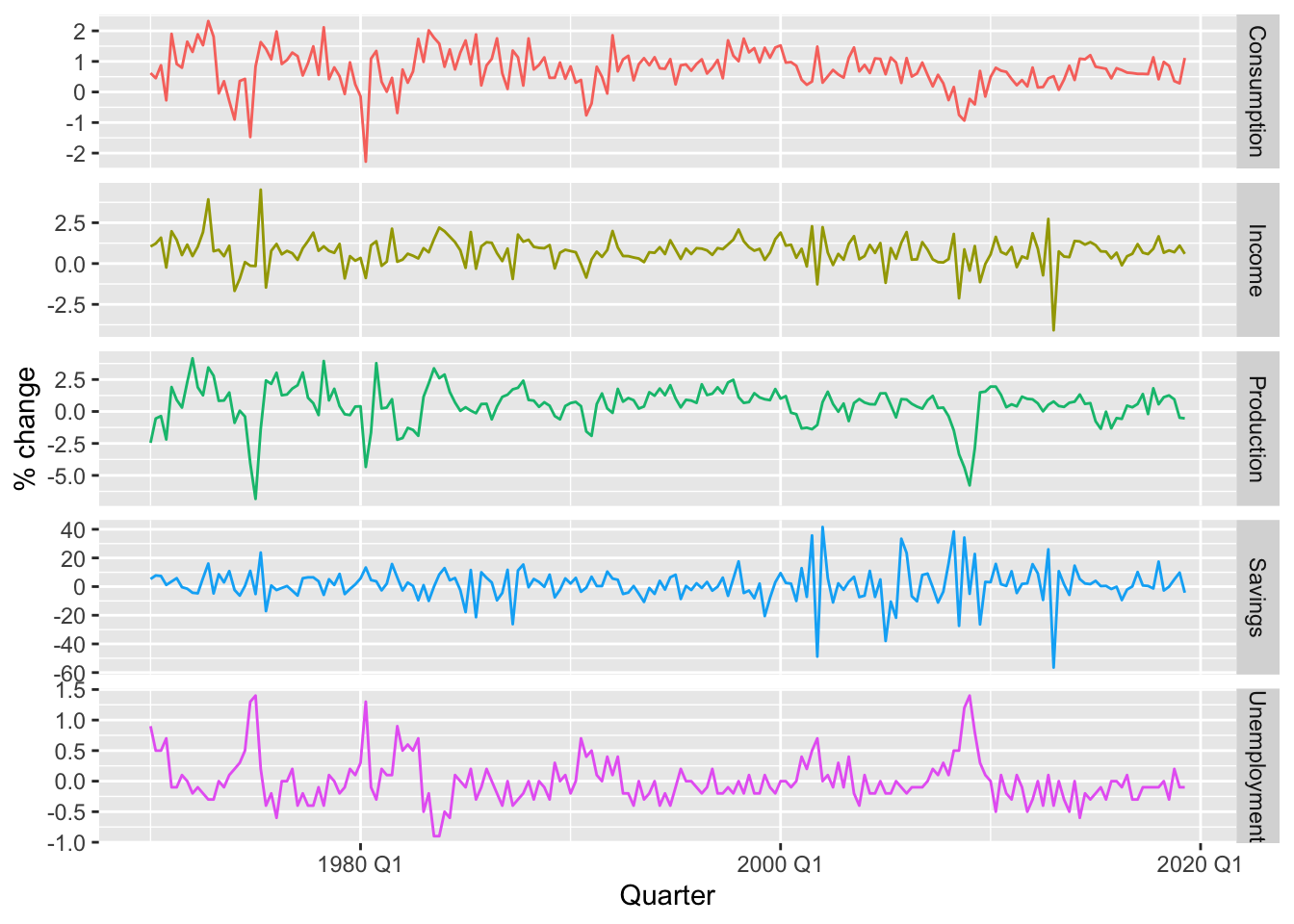
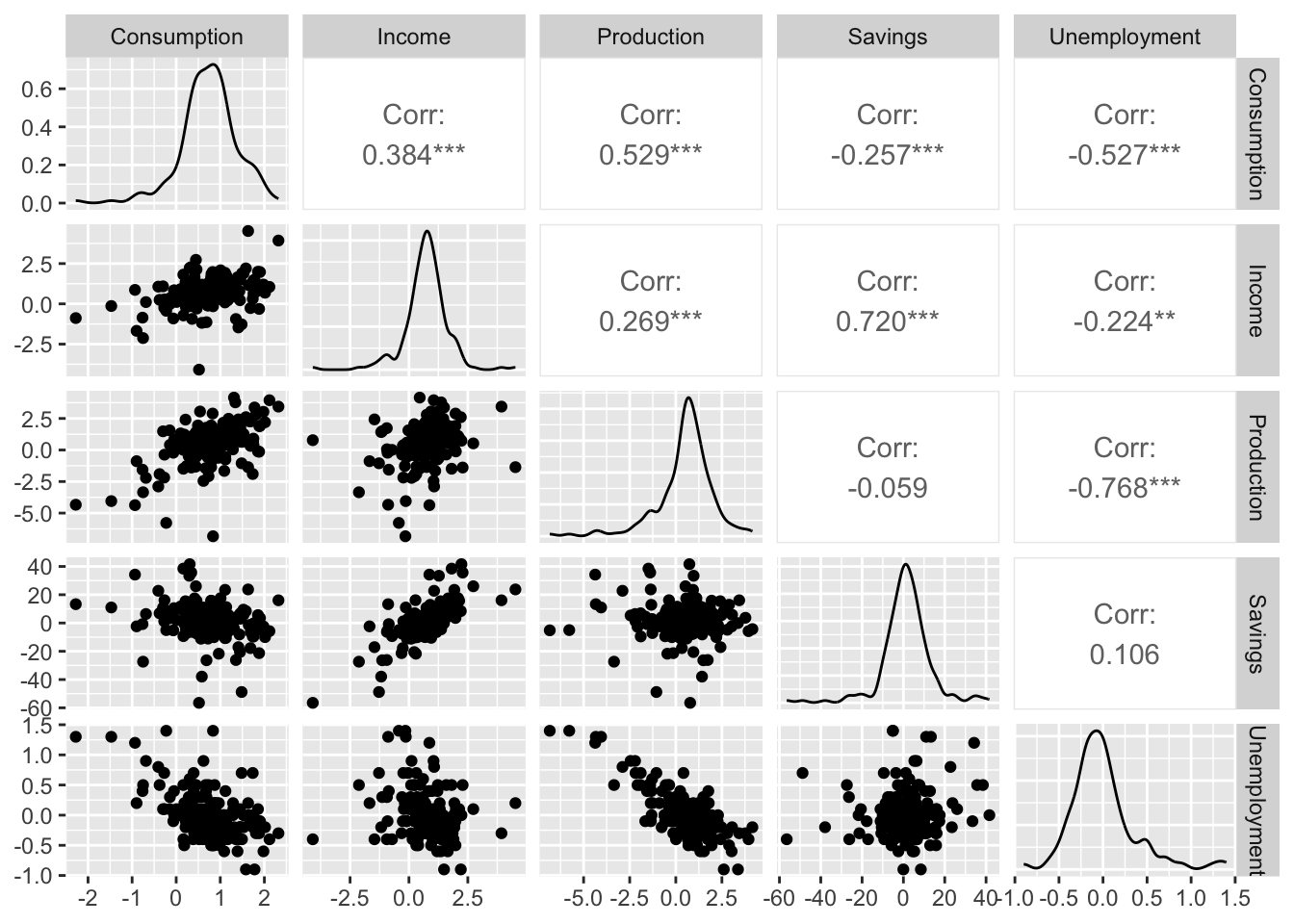
7.2.0.1 Example: US consumption expenditure
\[ y_t = \beta_0 + \beta_1x_{1,t} + \beta_2x_{2,t} + \beta_3x_{3,t} + \beta_4x_{4,t} + \varepsilon_t \]
- \(y\) is the percentage change in real personal consumption expenditure
- \(x_1\) is the percentage change in real personal disposable income
- \(x_2\) is the percentage change in industrial production
- \(x_3\) is the percentage change in personal savings
- \(x_4\) is the change in the unemployment rate
Fitting the model.
fit_lm <- us_change |>
model(lm = TSLM(Consumption ~ Income + Production +
Unemployment + Savings))
fit_lm |> report()## Series: Consumption
## Model: TSLM
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.90555 -0.15821 -0.03608 0.13618 1.15471
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.253105 0.034470 7.343 5.71e-12 ***
## Income 0.740583 0.040115 18.461 < 2e-16 ***
## Production 0.047173 0.023142 2.038 0.0429 *
## Unemployment -0.174685 0.095511 -1.829 0.0689 .
## Savings -0.052890 0.002924 -18.088 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.3102 on 193 degrees of freedom
## Multiple R-squared: 0.7683, Adjusted R-squared: 0.7635
## F-statistic: 160 on 4 and 193 DF, p-value: < 2.22e-167.2.1 Fitted values
Estimated coefficients:
\[ \hat y_t = \hat \beta_0 + \hat \beta_1x_{1,t} + \hat \beta_2x_{2,t} + ... + \hat \beta_kx_{k,t} \] > Note! The predictions of the data used to estimate the model on the training set, not genuine forecasts of future values of \(y\).
fit_lm |>
augment() |>
ggplot(aes(x = Quarter)) +
geom_line(aes(y = Consumption, color = 'Actual Values')) +
geom_line(aes(y = .fitted, color = 'Fitted Values')) +
labs(y = NULL,
title = 'Percentage change in US consumption expediture') +
scale_color_manual(values = c('Actual Values' = 'black', 'Fitted Values' = 'orange')) +
guides(color = guide_legend(title = NULL))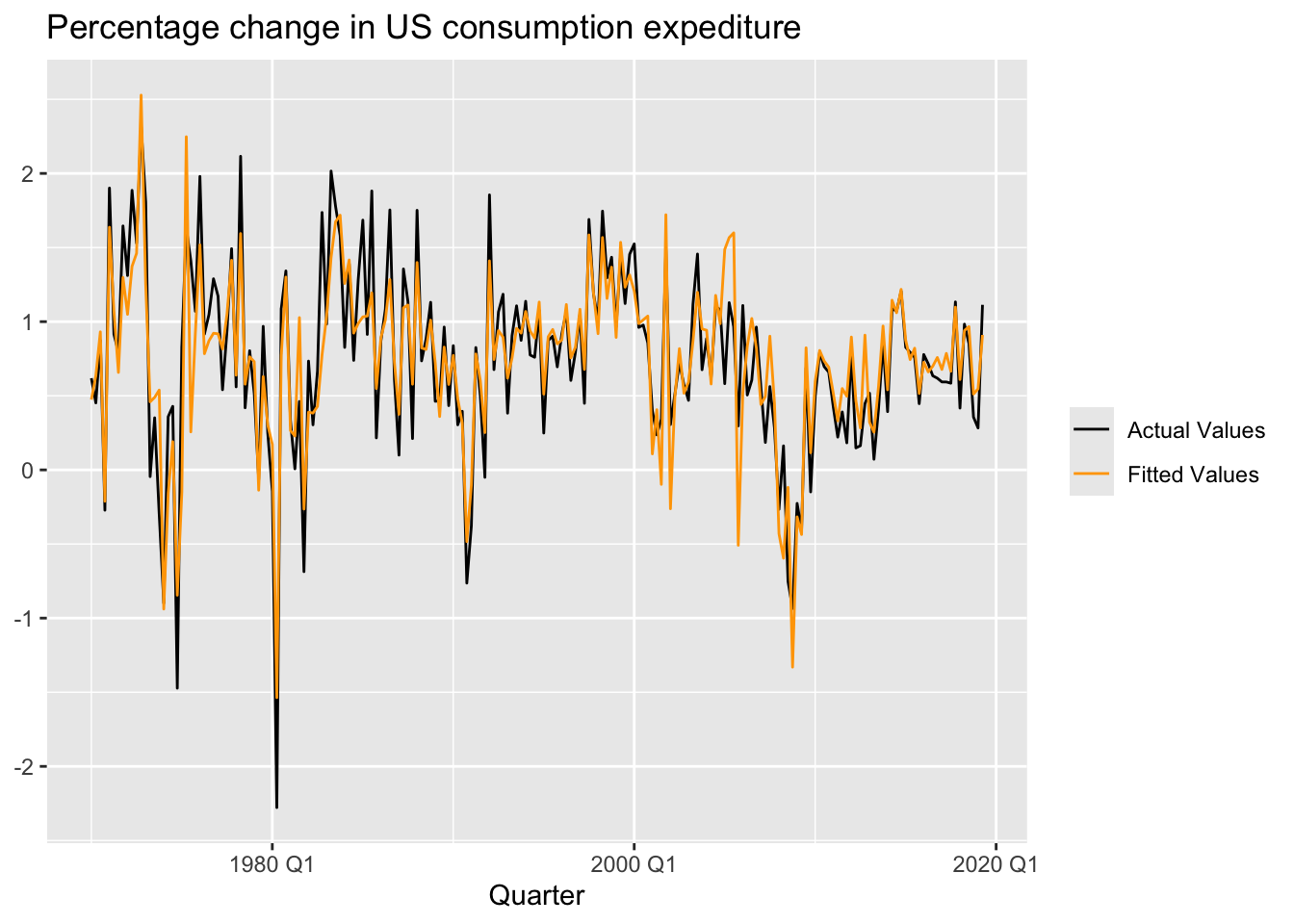
fit_lm |>
augment() |>
ggplot(aes(x = Consumption, y = .fitted)) +
geom_point() +
labs(y = 'Fitted (predicted values)',
x = 'Data (actual values)',
title = 'Percent change in US consumption expediture') +
geom_abline(intercept = 0, slope = 1, color = 'blue')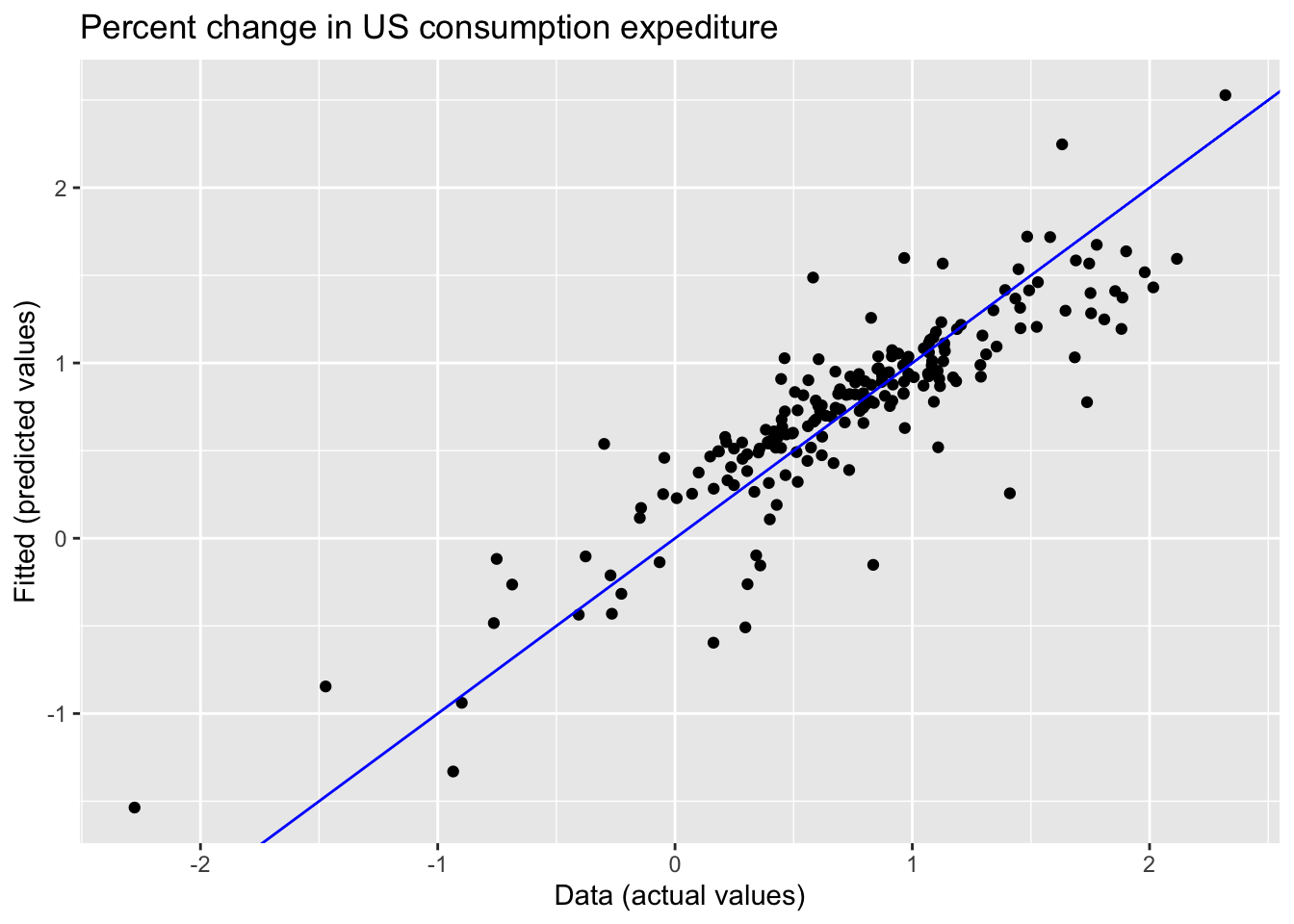
7.2.2 Goodness-of-fit
\(R^2\) is the coefficient of determination, which can be calculated as the square of the correlation between the observed \(y\) values and the predicted \(\hat y\) values.
\[ R^2 = \frac {\sum (\hat y_t - \bar y)^2} {\sum (y_t - \bar y)^2}, R^2 \in [0, 1] \] > Important! The value of \(R^2\) will never decrease when adding an extra predictor to the model and this can lead to over-fitting.
Validating a model’s forecasting performance on the test data is much better than measuring the \(R^2\) value on the training data.
7.2.3 Standard error of the regression
\(\hat \sigma_e\) is residual standard error.
\[ \hat \sigma_e = \sqrt {\frac 1 {T - k - 1} \sum_{t=1}^T e_t^2} \]
where \(k\) in the number of predictors in the model \(T-k-1\) because there is estimated \(k+1\) parameters (the intercept and a coefficient for each predictor variable)
7.3 Evaluating the regression model
\[ e_t = y_t - \hat y_t = y_t - \hat \beta_0 - \hat \beta_1x_{1,t} - \hat \beta_2x_{2,t} - ... - \hat \beta_kx_{k,t} \] Properties of residuals:
- \(\sum_{t=1}^T e_t = 0\) and \(\sum_{t=1}^T x_{k,t}e_t = 0\) for all \(k\) - \(\varepsilon_t\) have mean zero and are uncorrelated, \(NID(0, \sigma^2)\)
- \(\varepsilon_t\) are uncorrepated with each \(x_{j,t}\)
- Timeplot, ACF, Histogram (
gg_tsresiduals()) - Against predictors (non-linearity)
- Against fitted values (heteroscedasticity)
- Against predictors not in the model (include predictor in the model)
- Timeplot, ACF, Histogram (
Expect to see scatterplots resembling a horizontal band with no values too far from the band and no patterns such as curvature or increasing spread.
7.3.1 ACF plot of residuals
We should always look ar an ACF plot of the residuals to be sure there are no information left in the residual over which we should be accounted for in the model in order to obtain better forecast.
7.3.2 Histogram of residuals
We should always check whether the residuals are normally distributed using histogram, qq-plot, or/and formal tests. It does make the calculation of prediction intervals much easier.
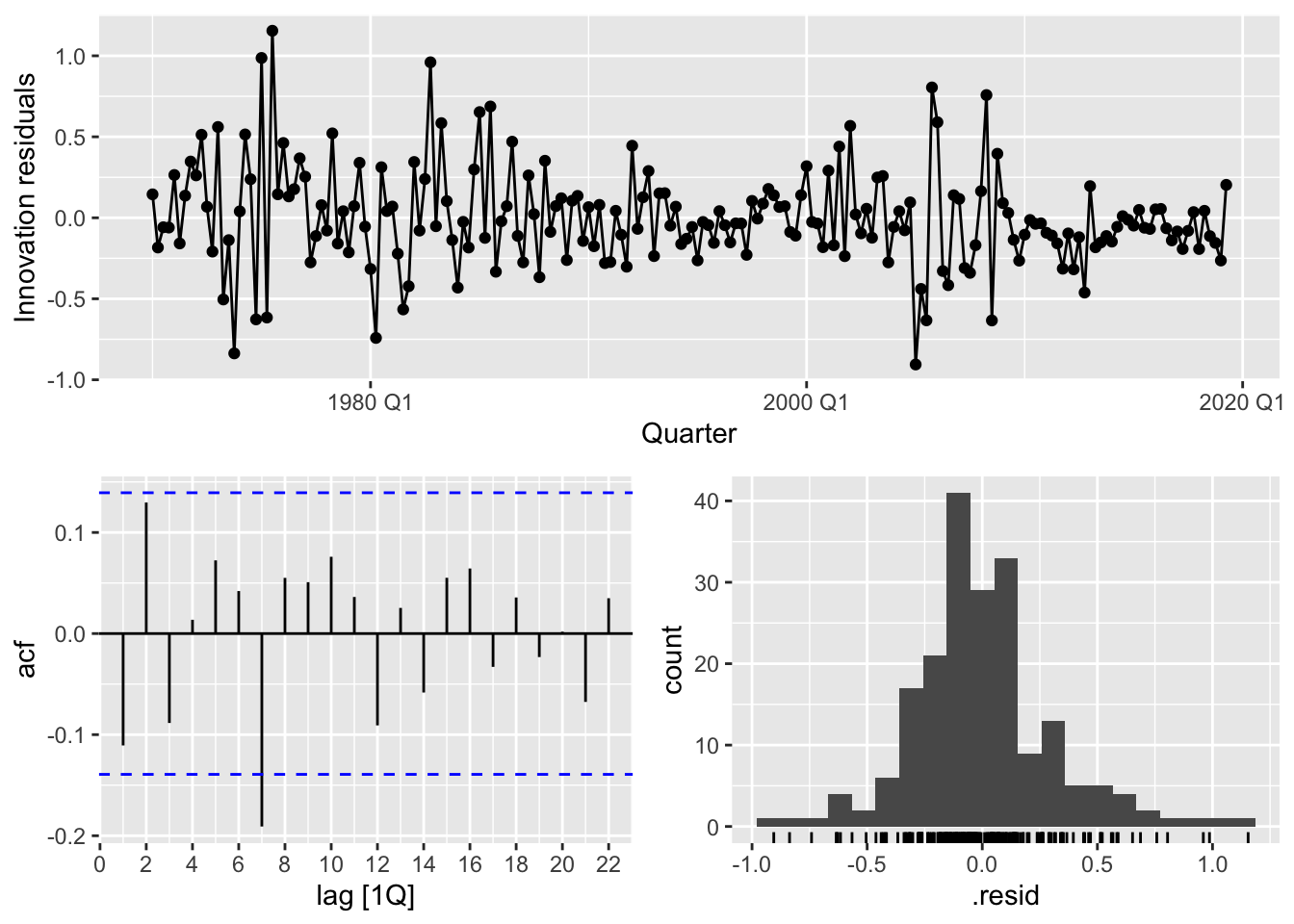
## # A tibble: 1 × 3
## .model lb_stat lb_pvalue
## <chr> <dbl> <dbl>
## 1 lm 18.9 0.0420Conclusion:
- Changing variation over time - heteroscedasticity could affect accuracy of prediction intervals
- The histogram is slightly skewed
- There is significant spike at lag 7.
7.3.3 Residual plots against predictors
We would expect the residuals to be randomly scattered without showing any systematic patterns.
Examine scatterplots of the residuals against each of the predictor variables. If the plots show a pattern then there is the relationship is nonlinear.
us_change |>
left_join(residuals(fit_lm), by = 'Quarter') |>
pivot_longer(Income:Unemployment, names_to = 'regressor', values_to = 'x') |>
ggplot(aes(x = x, y = .resid)) +
geom_point() +
facet_wrap(. ~ regressor, scales = 'free_x') +
labs(y = 'Residuals', x = '')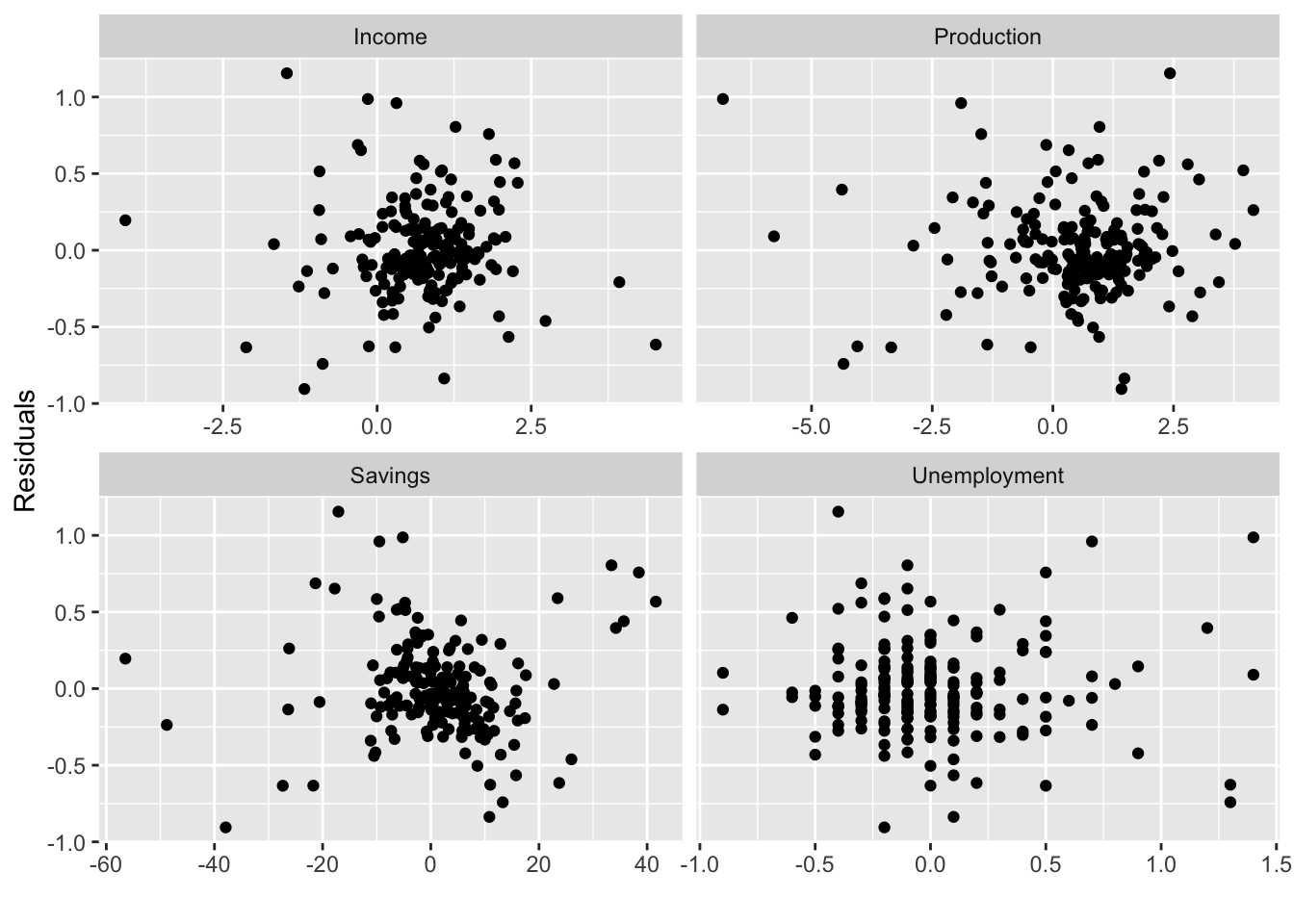
Important! Plot the residuals against any predictors that are not in the nodel. If any pattern are shown, these predictors are needed to be added to the model.
7.3.4 Residual plots against fitted values
A plot of the residuals against the fitted values should show no pattern, otherwise there may be heteroscedasticity in the errors (unconstant variance).
fit_lm |>
augment() |>
ggplot(aes(x = .fitted, y = .resid)) +
geom_point() +
labs(x = 'Fitted', y = 'Residuals', title = 'Fitted vs Residuals')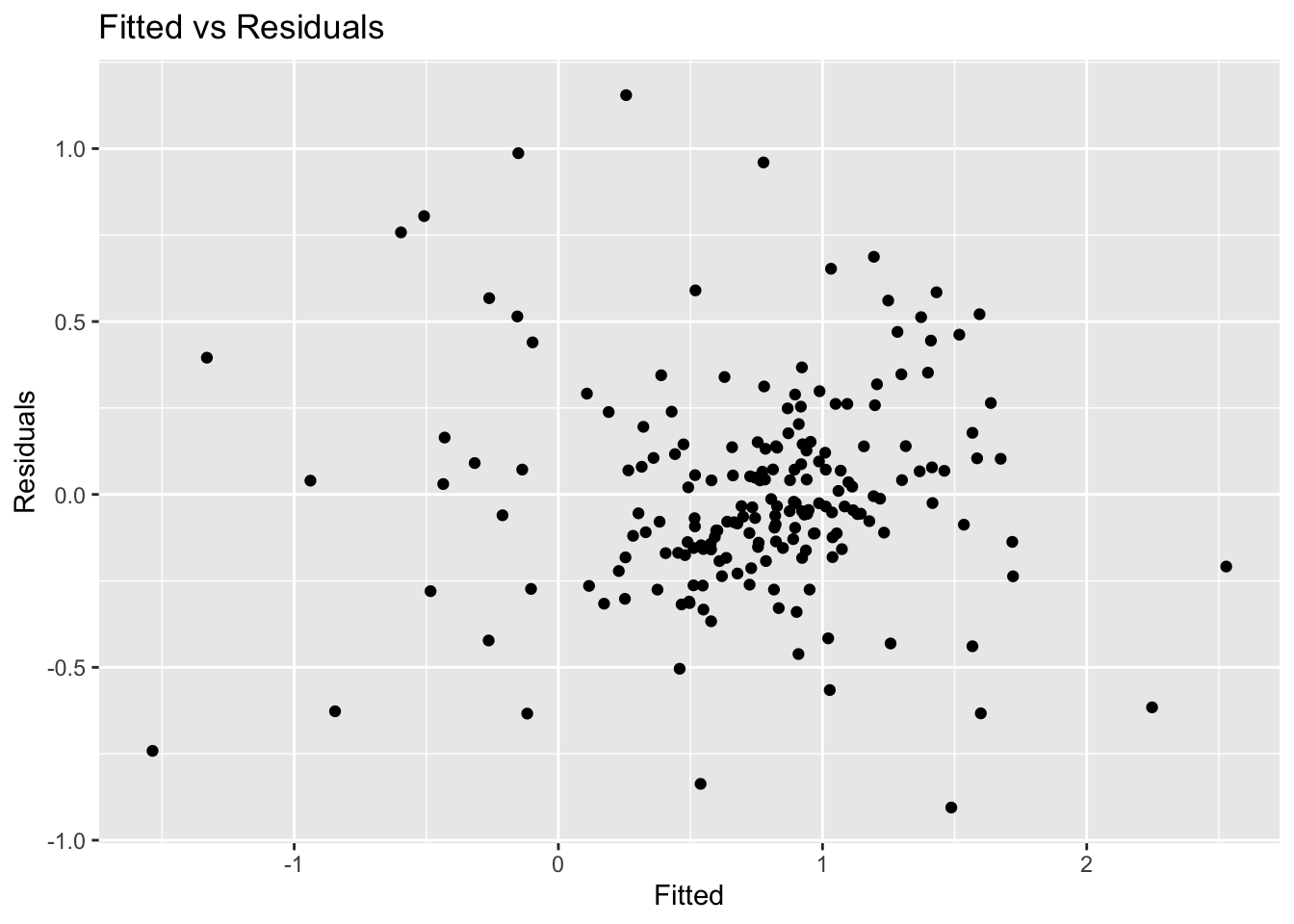
The error are homoscedastic.
7.3.5 Outliers and influential observations
Observations that have a large influence on the estimated coefficients of a regression model are called influential observations.
us_change |>
ggplot(aes(x = Income, y = Consumption)) +
geom_point() +
geom_smooth(method = 'lm', se = F)## `geom_smooth()` using formula = 'y ~ x'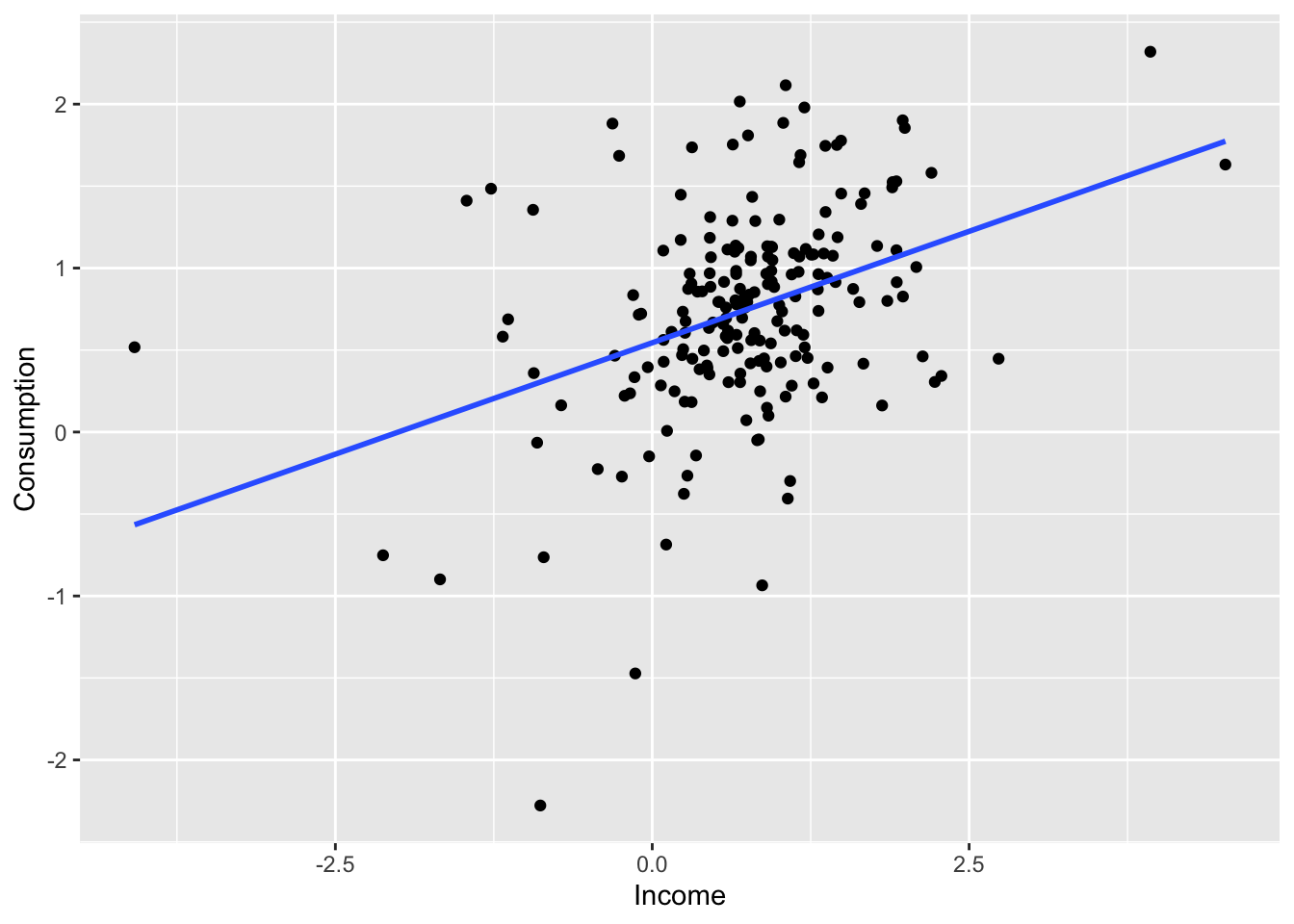
us_change2 <- us_change
bind_rows(us_change2,
us_change2 |>
new_data(n = 1, keep_all = T) |>
mutate(Consumption = -4, Income = 6)) |>
ggplot(aes(x = Income, y = Consumption)) +
geom_point() +
geom_smooth(method = 'lm', se = F)## `geom_smooth()` using formula = 'y ~ x'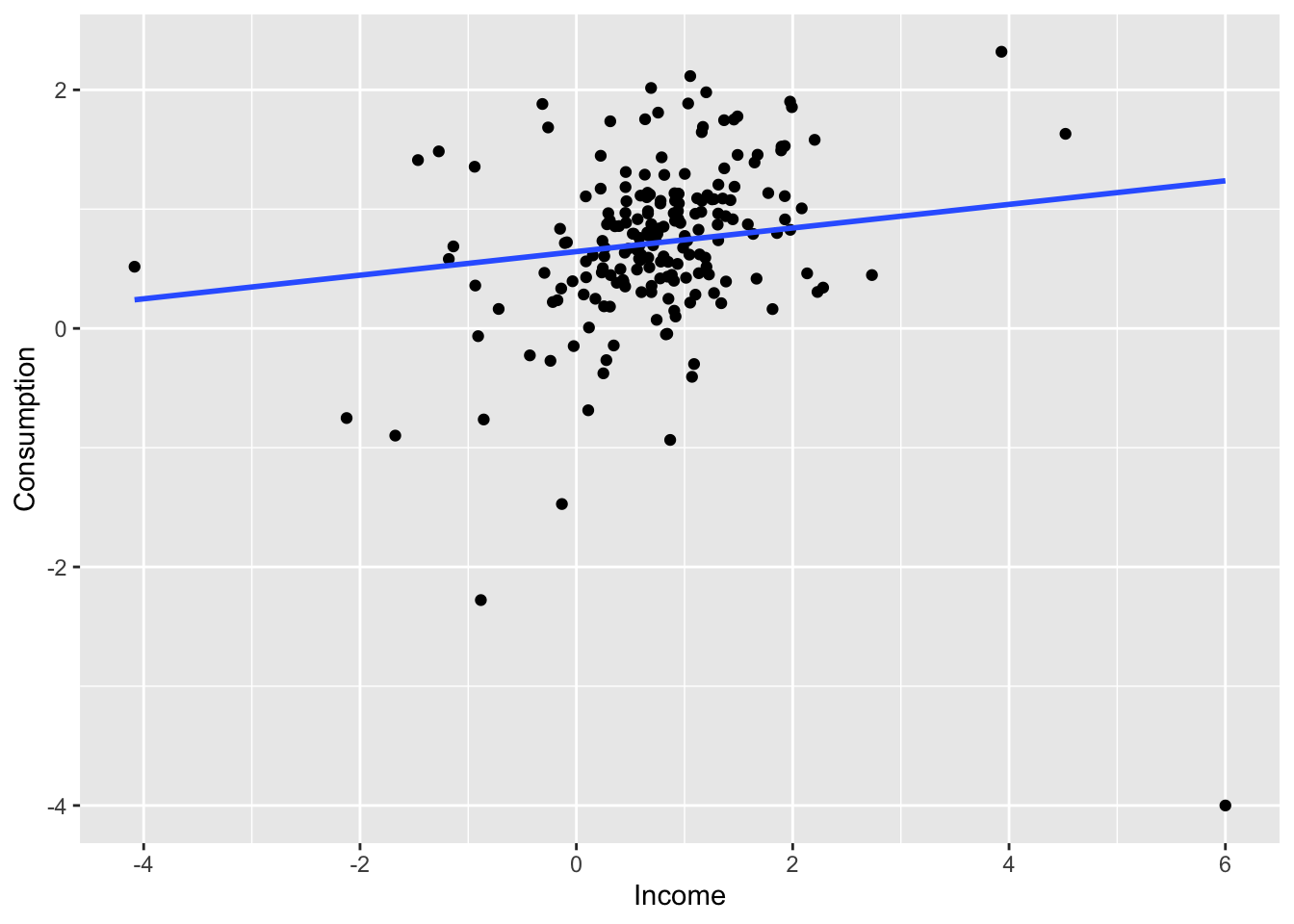
7.3.6 Spurious regression
fit <- aus_airpassengers |>
filter(Year <= 2011) |>
left_join(guinea_rice, by = 'Year') |>
model(TSLM(Passengers ~ Production))
report(fit)## Series: Passengers
## Model: TSLM
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.9448 -1.8917 -0.3272 1.8620 10.4210
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -7.493 1.203 -6.229 2.25e-07 ***
## Production 40.288 1.337 30.135 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.239 on 40 degrees of freedom
## Multiple R-squared: 0.9578, Adjusted R-squared: 0.9568
## F-statistic: 908.1 on 1 and 40 DF, p-value: < 2.22e-16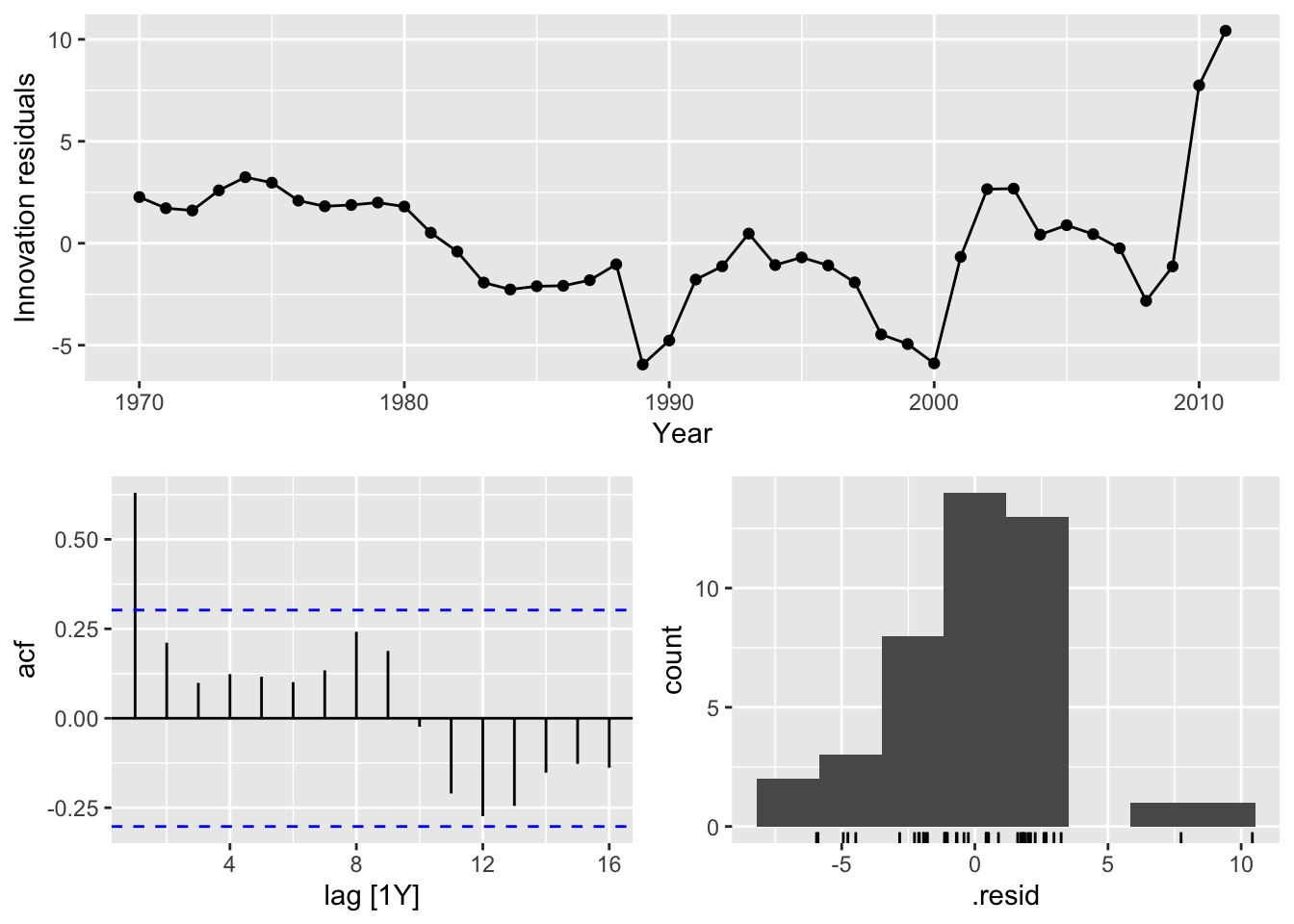
7.4 Some useful predictors
7.4.1 Trend
Linear trend:
- \(t = 1, 2, ..., T\)
- Using \(x_{1,t} = t\) as predictor
- Trend variable can be specified by
trend()in theTSLM() - Strong assumption that trend will continue
aus_airpassengers |>
model(TSLM(Passengers ~ trend())) |>
augment() |>
autoplot(Passengers) +
geom_line(aes(y = .fitted), color='blue') +
labs(title = 'Linear trend of number of air passengers in Australia')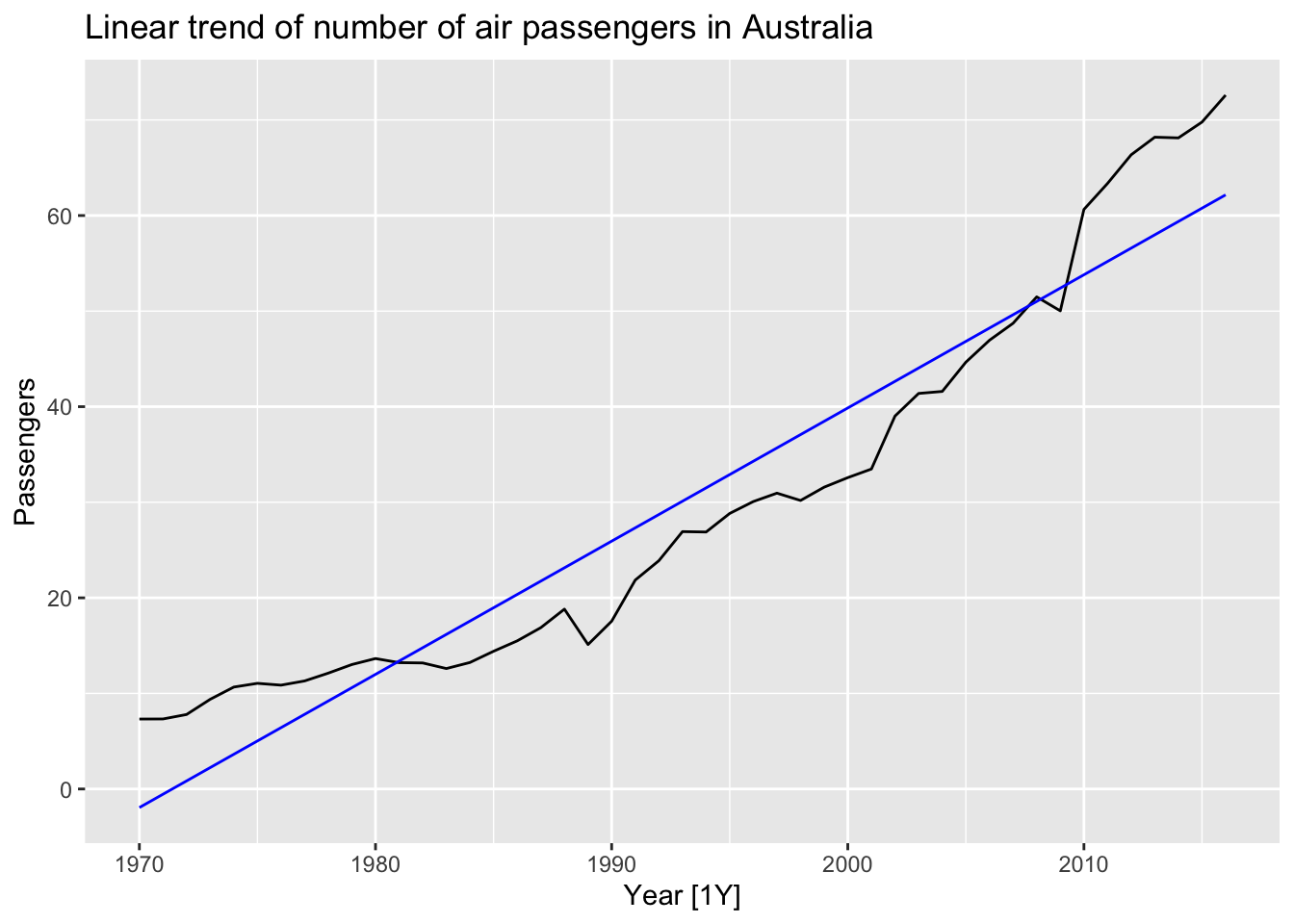
7.4.2 Dummy variables
To make numerical variable from categorical variable use dummy variable which takes 1 if yeas and 0 if no. To remove the effect of outliers, for example if special event has occured, saying the Rio de Janeiro summer Olympics in 2016, the dummy variable takes value 1 for the observations which have overlapped with the games and 0 everywhere else.
TSLM()will automatically handle this case if you specify a factor variable as a predictor.
7.4.3 Seasonal dummy variables
For quarterly data.
| \(d_{1, t}\) | \(d_{2, t}\) | \(d_{3, t}\) | |
|---|---|---|---|
| Q1 | 1 | 0 | 0 |
| Q2 | 0 | 1 | 0 |
| Q3 | 0 | 0 | 1 |
| Q4 | 0 | 0 | 0 |
| Q1 | 1 | 0 | 0 |
The interpretation of each of the coefficients associated with the dummy variables is that it is a measure of the effect of that category relative to the omitted category. In the above example, the coefficient of \(d_{1,t}\) associated with Q1 will measure the effect of Q1 on the forecast variable compared to the effect of Q4 (omitted dummy variable).
The model using a linear trend and quarterly dummy variables.
\[ y_t = \beta_0 + \beta_1t + \beta_2d_{2, t} + \beta_3d_{3, t} + \beta_4d_{4, t} + \varepsilon_t \]
where \(d_{i, t} = 1\) if \(t\) is in quarter \(i\) and 0 otherwise.
recent_production <- aus_production |>
filter(year(Quarter) >= 1992)
recent_production |>
autoplot(Beer) +
labs(y = 'Megalitres',
title = 'Australian quarterly beer production')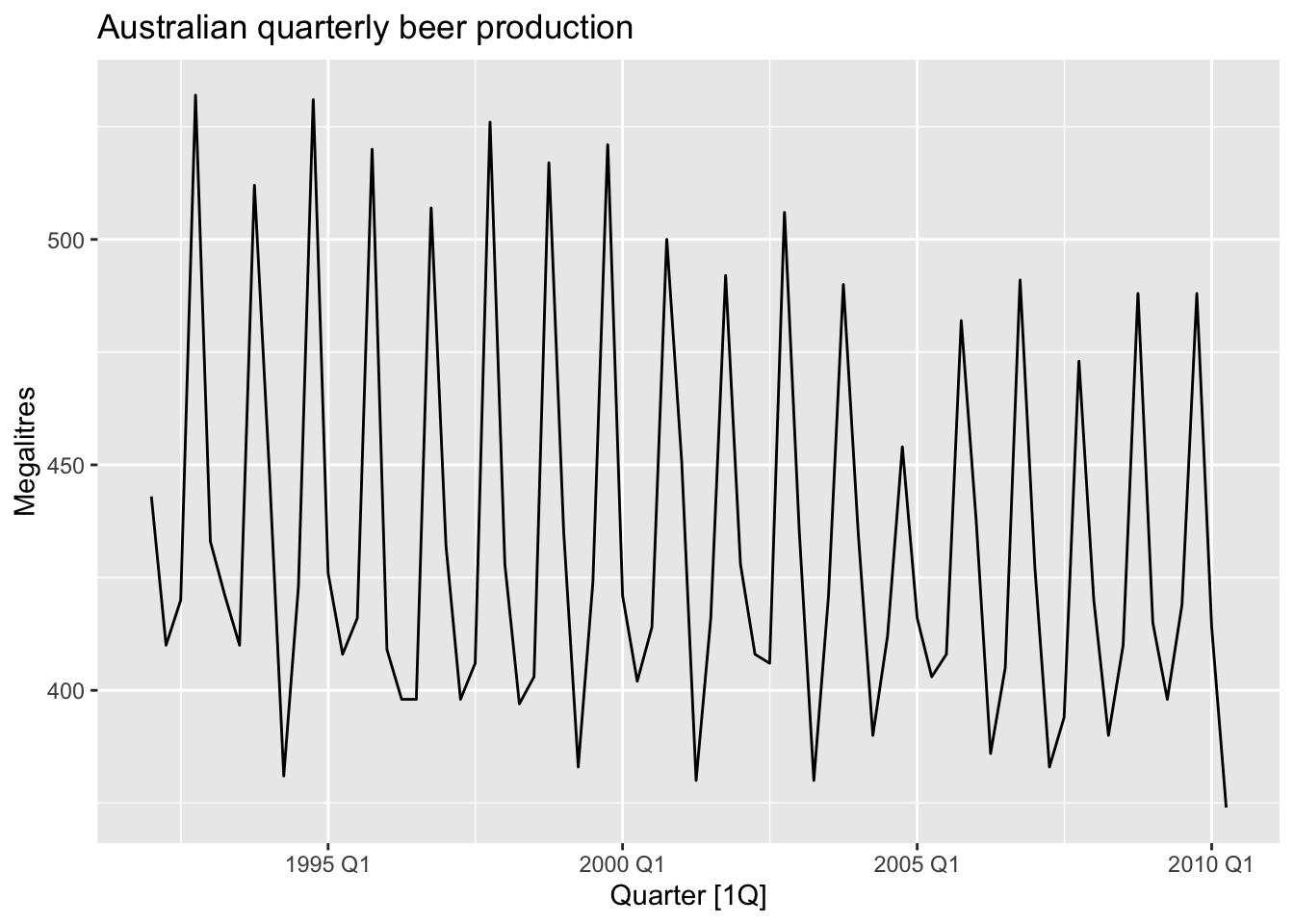
## Series: Beer
## Model: TSLM
##
## Residuals:
## Min 1Q Median 3Q Max
## -42.9029 -7.5995 -0.4594 7.9908 21.7895
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 441.80044 3.73353 118.333 < 2e-16 ***
## trend() -0.34027 0.06657 -5.111 2.73e-06 ***
## season()year2 -34.65973 3.96832 -8.734 9.10e-13 ***
## season()year3 -17.82164 4.02249 -4.430 3.45e-05 ***
## season()year4 72.79641 4.02305 18.095 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 12.23 on 69 degrees of freedom
## Multiple R-squared: 0.9243, Adjusted R-squared: 0.9199
## F-statistic: 210.7 on 4 and 69 DF, p-value: < 2.22e-16Interpretation: The first quarter variable has been omitted, so the coefficients associated with the other quarters are measures of the difference between those quarters and the first quarter. There is an average downward trend of -0.34 megalitres per quarter. On average, the second quarter has production of 34.7 megalitres lower than the first quarter, the third quarter has production of 17.8 megalitres lower than the first quarter, and the fourth quarter has production of 72.8 megalitres higher than the first quarter.
7.4.3.1 Beware of using dummy variables
- Using one dummy for each category gives too many dummy variables
- The regression will then be singular and inestimable
- Either omit the constant, or omit the dummy for one category
- The coefficients of the dummies are relative to the omitted category
7.4.3.2 Example
fit_beer |>
augment() |>
ggplot(aes(x = Quarter)) +
geom_line(aes(y = Beer, color = 'Data')) +
geom_line(aes(y = .fitted, color = 'Fitted')) +
scale_color_manual(values = c(Data = 'black', Fitted = 'orange')) +
labs(y = 'Megalitres',
title = 'Australian quarterly beer production') +
guides(color = guide_legend(title = 'Series'))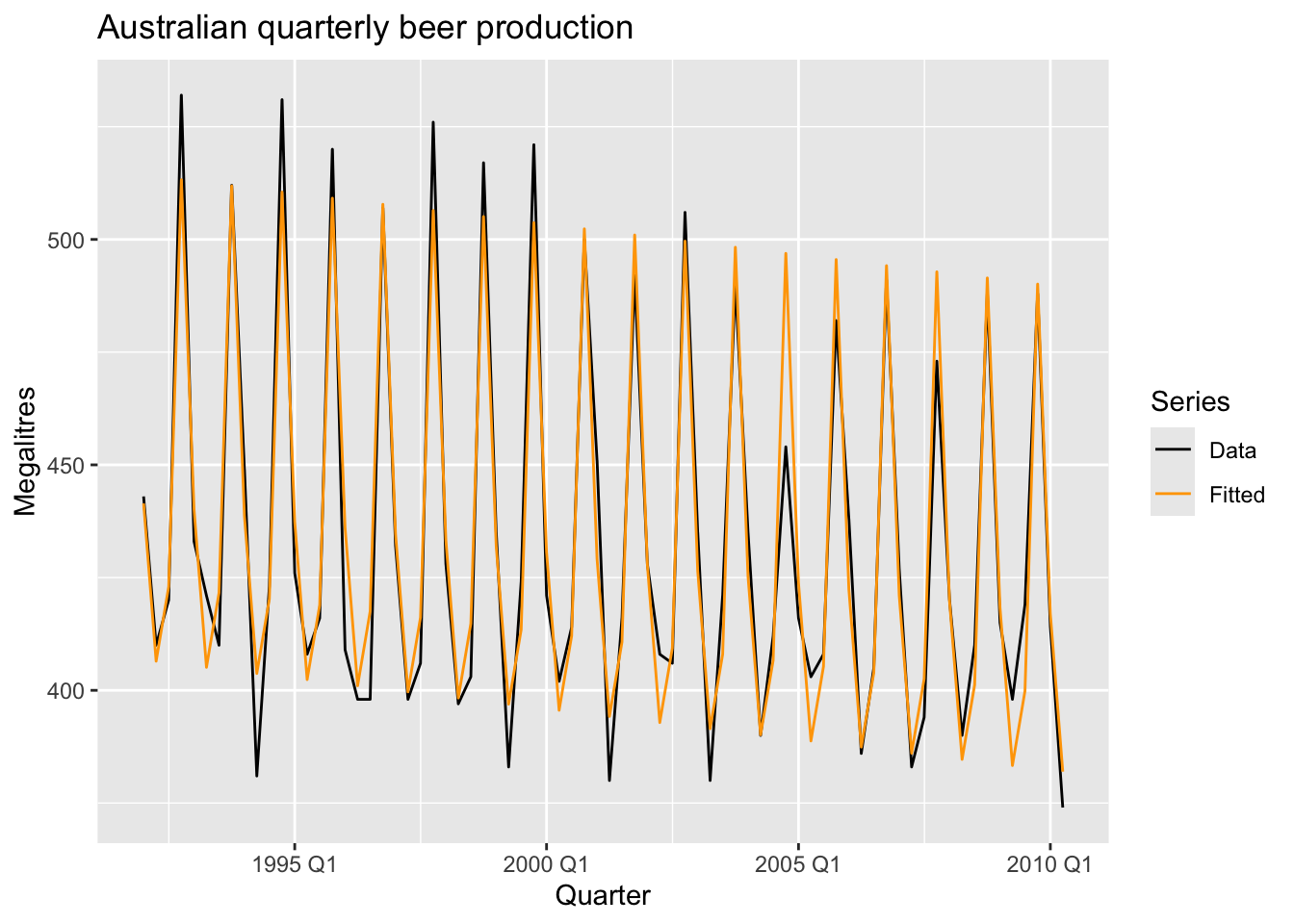
fit_beer |>
augment() |>
ggplot(aes(x = Beer, y = .fitted,
color = factor(quarter(Quarter)))) +
geom_point() +
labs(y = "Fitted", x = "Actual values",
title = "Australian quarterly beer production") +
geom_abline(intercept = 0, slope = 1) +
guides(colour = guide_legend(title = "Quarter"))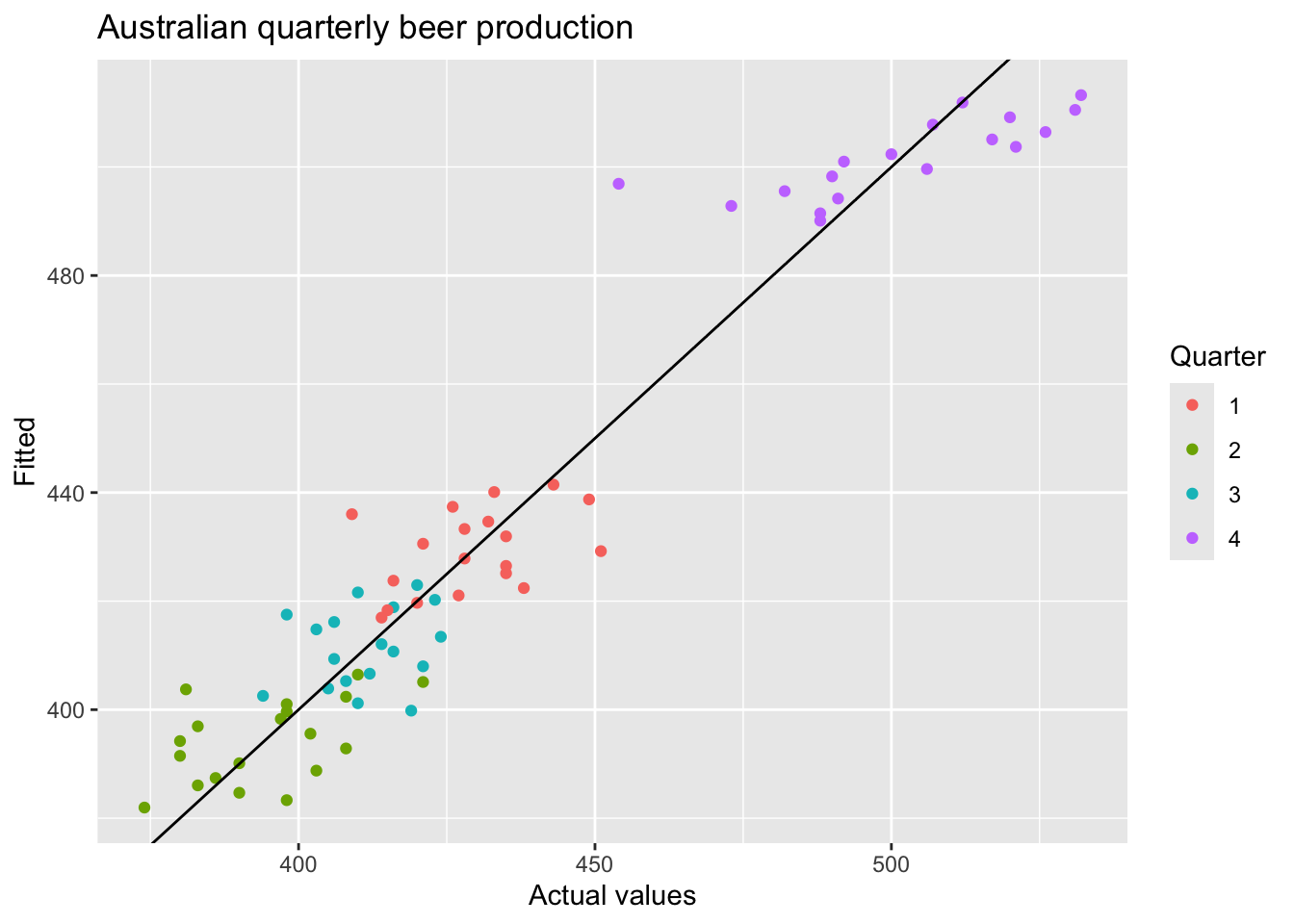
7.4.3.3 Uses of dummy variables
Seasonal dummies
- For quarterly data use 3 dummies
- For monthly data use 11 dummies
- For daily data use 6 dummies
- For weekly data DO NOT USE dummies, use Fourier instead.
Outliers
- If there is an outlier, use a dummy variable to remove its effect.
Public holidays
- For daily data: if it is a public holiday, dummy = 1, otherwise dummy = 0
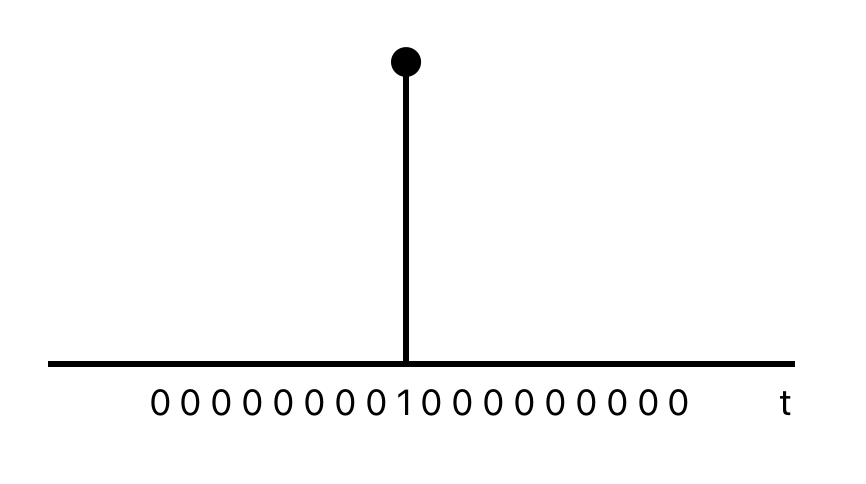
7.4.4 Intervention variables
Spikes
Equivalent to a dummy variable for handling an outlier.
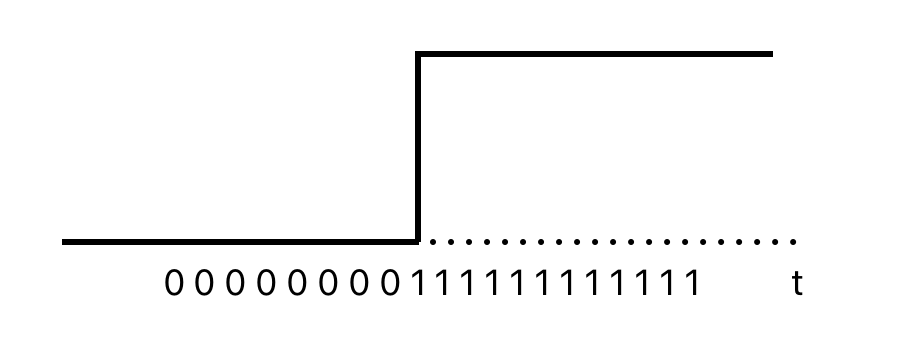
Steps
Variable takes value 0 before the intervention and 1 afterwards.
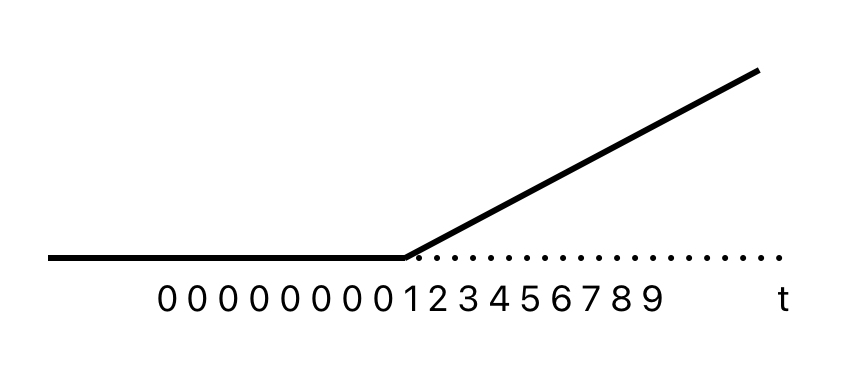
 Change of slope
Change of slope
Variables take values 0 before the intervention and values {1, 2, 3, …} afterwards.
###Holidays
For monthly data
- Christmas: always in December so part of monthly seasonal effect
- Easter: use a dummy variable \(v_t = 1\) if any part of Easter is in that month, \(v_t = 0\) otherwise.
- Ramadan and Chinese new year similar
Important! If the public holiday starts in one month and finishes in the another, the dummy variable is split proportionally between months.
7.4.5 Trading days
- The number of trading days in each month can be included as a predictor
- Alternative:
- \(x_1\) = number of Mondays in month
- \(x_2\) = number of Tuesdays in month
- \(x_3\) = number of Wednesday in month
- \(x_4\) = number of Thursday in month
- \(x_5\) = number of Friday in month
- \(x_6\) = number of Saturday in month
- \(x_7\) = number of Sunday in month
7.4.6 Distributed lags
Since the effect of advertising can last beyond the actual campaign, we need to include lagged values of advertising expenditure.
- \(x_1\) = advertising for previous month
- \(x_2\) = advertising for two months previously
- …
- \(x_2\) = advertising for \(m\) months previously
- For long seasonal perions
- An alternative to using seasonal dummy variables
If \(m\) is the seasonal pattern, then
\[ x_{1,t} = sin\left(\frac {2\pi t} m \right), x_{2,t} = cos \left( \frac {2\pi t} m \right), \\ x_{3,t} = sin\left(\frac {4\pi t} m \right), x_{4,t} = cos \left( \frac {4\pi t} m \right), \\ x_{5,t} = sin\left(\frac {6\pi t} m \right), x_{6,t} = cos \left( \frac {6\pi t} m \right), \\ \]
## Series: Beer
## Model: TSLM
##
## Residuals:
## Min 1Q Median 3Q Max
## -42.9029 -7.5995 -0.4594 7.9908 21.7895
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 446.87920 2.87321 155.533 < 2e-16 ***
## trend() -0.34027 0.06657 -5.111 2.73e-06 ***
## fourier(K = 2)C1_4 8.91082 2.01125 4.430 3.45e-05 ***
## fourier(K = 2)S1_4 -53.72807 2.01125 -26.714 < 2e-16 ***
## fourier(K = 2)C2_4 -13.98958 1.42256 -9.834 9.26e-15 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 12.23 on 69 degrees of freedom
## Multiple R-squared: 0.9243, Adjusted R-squared: 0.9199
## F-statistic: 210.7 on 4 and 69 DF, p-value: < 2.22e-16\(K = m/2\), where \(m\) is the seasonal period. Using maximum allowed \(K\) produces the results that are identical to those when using seasonal dummy variables.
recent_production |>
model(trend_season_linear_regression = TSLM(Beer ~ trend() + season()),
harmonic_regression = TSLM(Beer ~ trend() + fourier(K = 2))) |>
report()## Warning in report.mdl_df(model(recent_production, trend_season_linear_regression = TSLM(Beer ~ : Model reporting is only supported for individual models, so a glance
## will be shown. To see the report for a specific model, use `select()` and `filter()` to identify a single model.## # A tibble: 2 × 15
## .model r_squared adj_r_squared sigma2 statistic p_value df log_lik AIC AICc BIC CV deviance df.residual rank
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int>
## 1 trend_season_linear_regression 0.924 0.920 150. 211. 6.97e-38 5 -288. 377. 379. 391. 160. 10320. 69 5
## 2 harmonic_regression 0.924 0.920 150. 211. 6.97e-38 5 -288. 377. 379. 391. 160. 10320. 69 57.5 Selecting predictors
The measures of predictive accuracy which can be used to find the best model:
## # A tibble: 1 × 5
## adj_r_squared CV AIC AICc BIC
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0.763 0.104 -457. -456. -437.7.5.1 Adjusted \(R^2\)
\(R^2\) (coefficient of determination) measures how well the model fits the historical data, but not well the model will forecast future data.
\[ R^2 = \frac {\sum (\hat y_t - \bar y)^2} {\sum (y_t - \bar y)^2} \]
Minimising the SSE is equivalent to maximising \(R^2\). It is not a valid way of selecting predictors.
\[ SSE = \sum_{t=1}^T e_t^2 \] Adjusted \(R^2\) (\(\bar R^2\)) will no longer increase with each added predictor.
\[ Adj. R^2 = \bar R^2 = 1 - (1-R^2)\frac {T-1} {T-k-1} \]
where \(T\) is the number of observations, \(k\) is the number of predictors. Maximising \(\bar R^2\) is equivalent to minimising the standard error \(\hat \sigma^2\).
7.5.2 Cross-validation
- Remove observation \(t\) from the data set, and fit the model using the remaining data.Then compute the error (\(e_t^* = y_t - \hat y_t\)) for the omitted observation.
- Repeat step 1 for \(t = 1,2,...,T\)
- Compute the MSE from \(e_1^*,...,e_T^*\) - CV
Note! The best model is the one with the smallest value of CV
7.5.3 Akaike’s Information Criterion
\[ AIC = T \times log \left( \frac {SSE} T\right) + 2(k + 2) \] where \(T\) is the number of observations used for estimation and \(k\) is the number of predictors in the model.
Note! The model with the minimum value of the AIC is often the best model for forecasting. For large values of \(T\), minimising the AIC is equivalent to minimising the CV value.
7.5.4 Corrected Akaike’s Information Criterion
\[ AIC_c = AIC + \frac {2(k+1)(k+3)} {T-k-3} \] > Note! The model with the minimum value of the \(AIC_c\) is often the best model for forecasting.
7.5.5 Schwarz’s Bayesian Information Criterion
\[ BIC = T \times log \left( \frac {SSE} T \right) + (k+2) \times log (T) \] > Note! The model with the minimum value of the \(BIC\) is often the best model for forecasting.
7.5.6 Stepwise regression
Backwards stepwise regression:
- Start with the model containing all potential predictors.
- Remove one predictor at a time. Keep the model if it improves the measure of predictive accuracy.
- Iterate until no further improvement.
If the number of predictors is too large, use forward stepwise regression instead.
- Start with a model that includes only the intercept.
- Predictors are added one at a time, and the one that most improves the measure of predictive accuracy is retained in the model.
- The procedure is repeated until no further improvement can be achieved.
Note! Any stepwise approach is not guaranteed to lead to the best possible model, but it almost always leads to a good model.
7.6 Forecasting with regression
recent_production <- aus_production |>
filter(year(Quarter) >= 1992)
fit_beer <- recent_production |>
model(TSLM(Beer ~ trend() + season()))
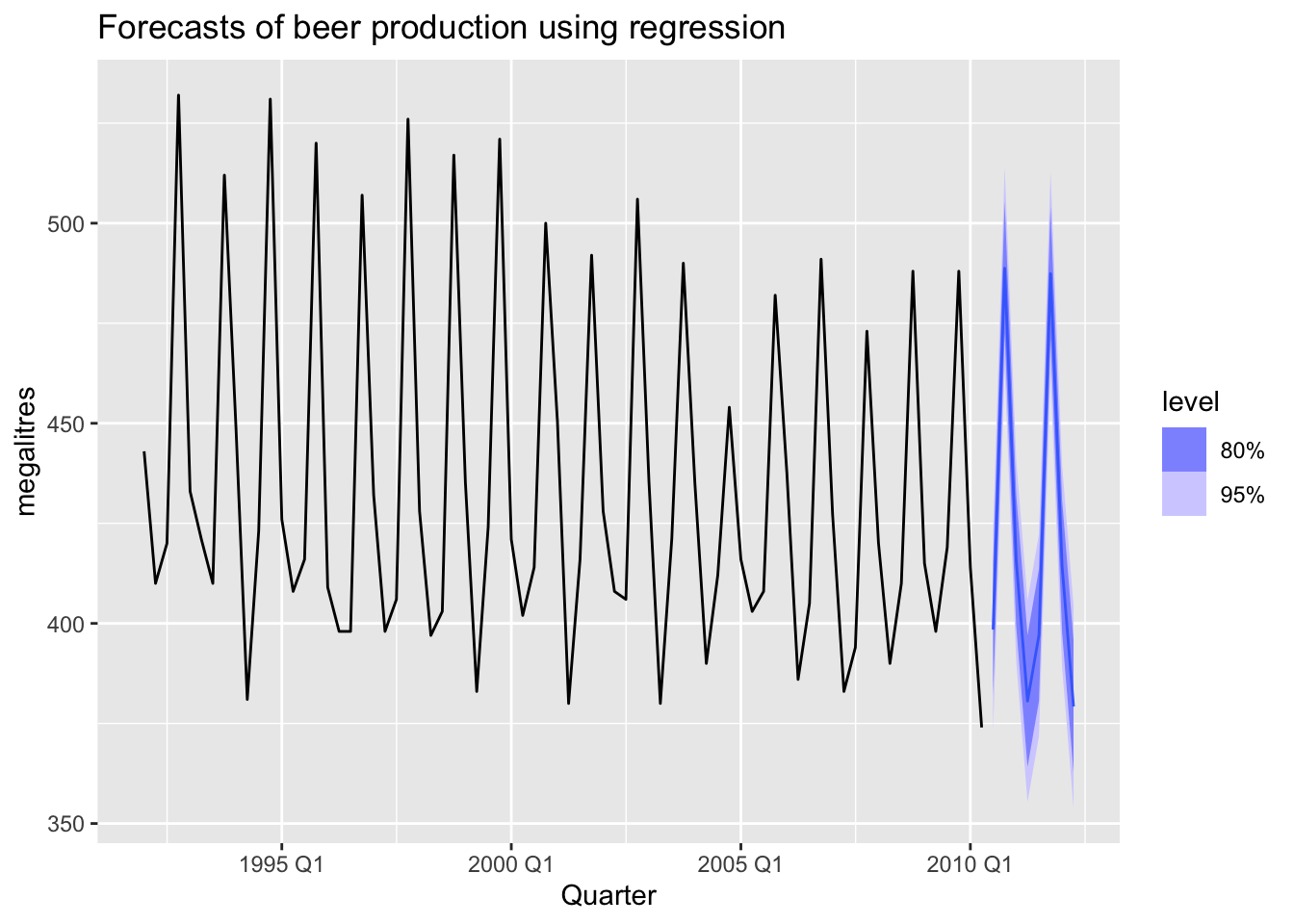
fc_beer <- fit_beer |> forecast()
fc_beer |>
autoplot(recent_production) +
labs(
title = "Forecasts of beer production using regression",
y = "megalitres"
)
7.6.1 Scenario based forecasting
fit <- us_change |>
model(
lm = TSLM(Consumption ~ Income + Savings + Unemployment)
)
future_scenarios <- scenarios(
Increase = new_data(us_change, 4) |>
mutate(Income = 1, Savings = 0.5, Unemployment = 0),
Decrease = new_data(us_change, 4) |>
mutate(Income = -1, Savings = -0.5, Unemployment = 0),
names_to = 'Scenario'
)
fc <- fit |> forecast(new_data = future_scenarios)
us_change |>
autoplot(Consumption) +
autolayer(fc) +
labs(title = "US consumption", y = "% change")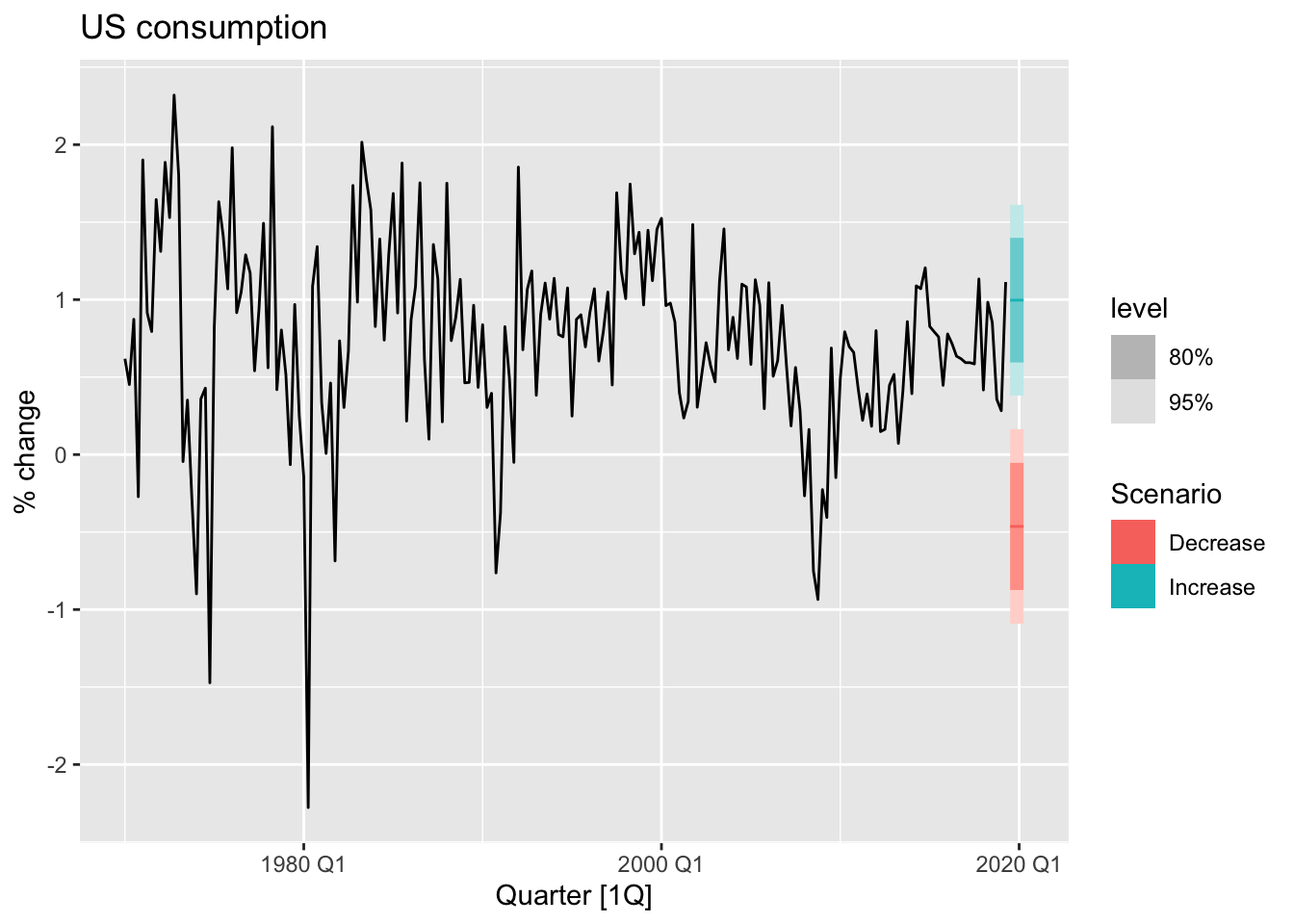
7.6.2 Prediction intervals
fit_cons <- us_change |>
model(TSLM(Consumption ~ Income))
new_cons <- scenarios(
"Average increase" = new_data(us_change, 4) |>
mutate(Income = mean(us_change$Income)),
"Extreme increase" = new_data(us_change, 4) |>
mutate(Income = 12),
names_to = "Scenario"
)
fcast <- forecast(fit_cons, new_cons)
us_change |>
autoplot(Consumption) +
autolayer(fcast) +
labs(title = "US consumption", y = "% change")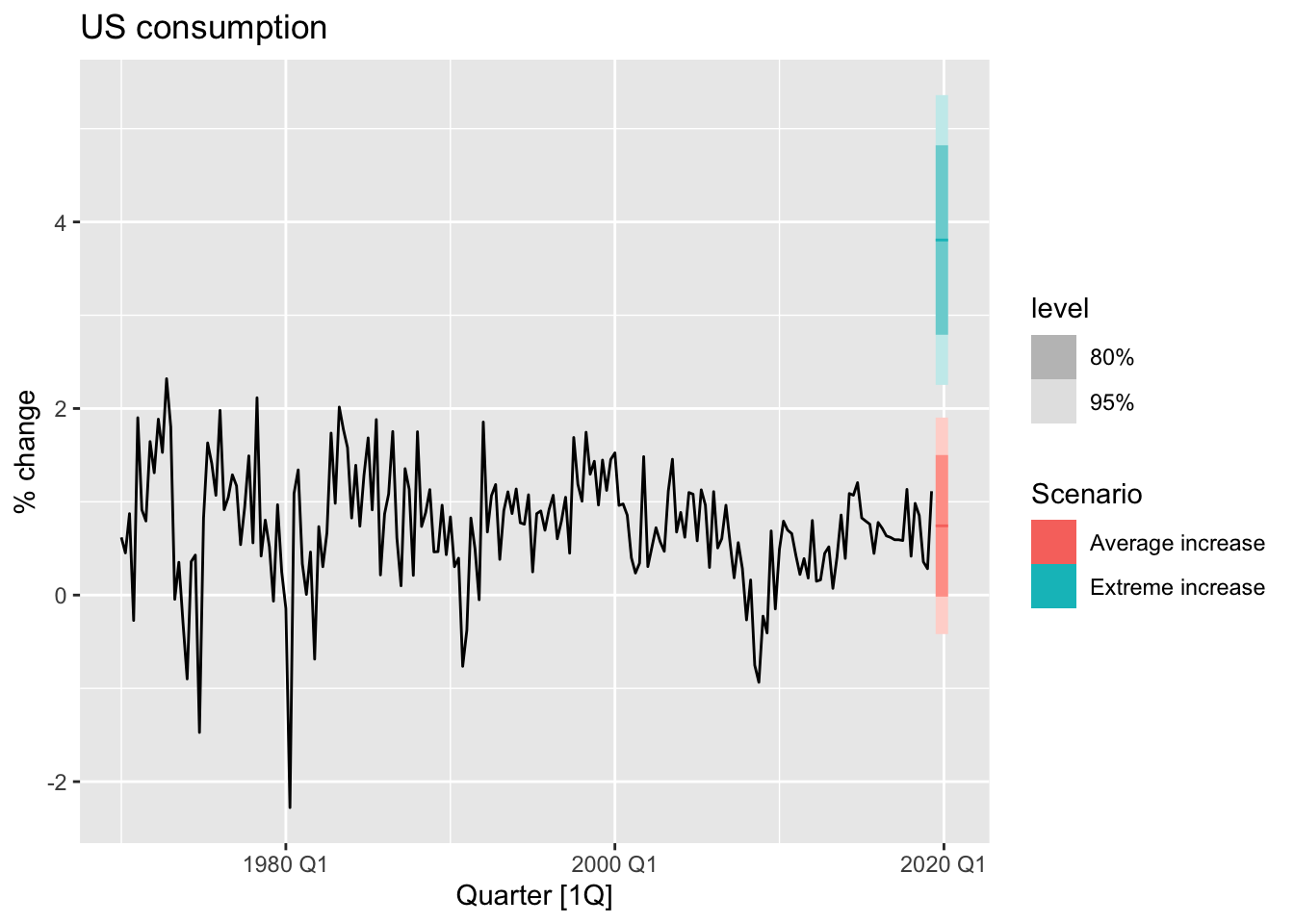
7.7 Nonlinear regression
Non-linear regression: \[ ln(y) = \beta_0 + \beta_1ln(x) +\varepsilon \]
\(\beta_1\) is the average percentage change in \(y\) resulting from a 1% increaqsing in \(x\). In the case what variable \(x\) contains zeros, we use the transformation \(ln(x+1)\).
7.7.1 Forecasting with a nonlinear trend
boston_men <- boston_marathon |>
filter(Year >= 1924) |>
filter(Event == "Men's open division") |>
mutate(Minutes = as.numeric(Time)/60)
# linear trend
boston_men |>
autoplot(Minutes) +
geom_smooth(method = 'lm', se = FALSE) +
labs(title = 'Boston marathon winning times')## `geom_smooth()` using formula = 'y ~ x'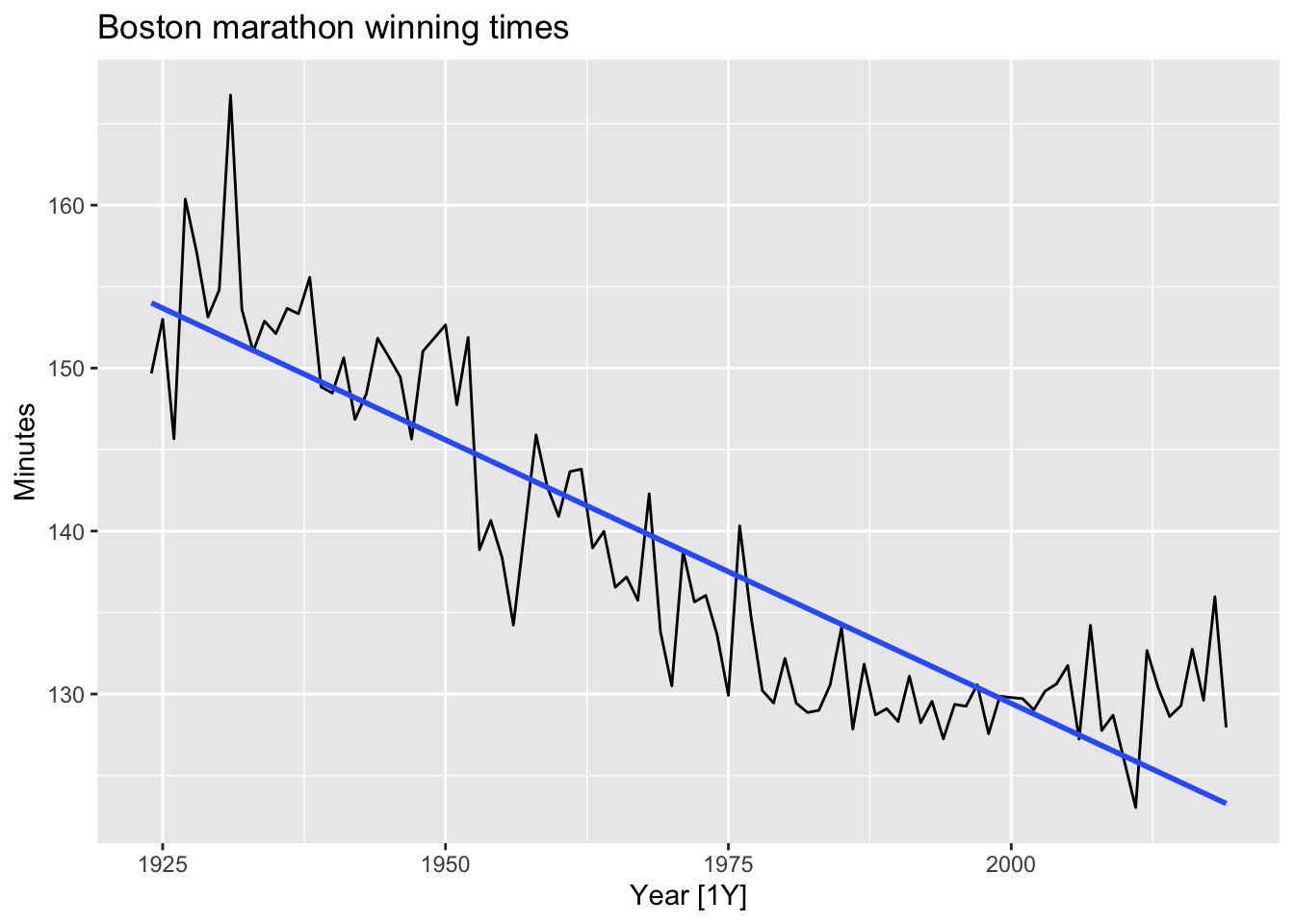
# residuals from linear trend
boston_men |>
model(TSLM(Minutes ~ trend())) |>
gg_tsresiduals() +
labs(title = 'Residuals from a linear trend')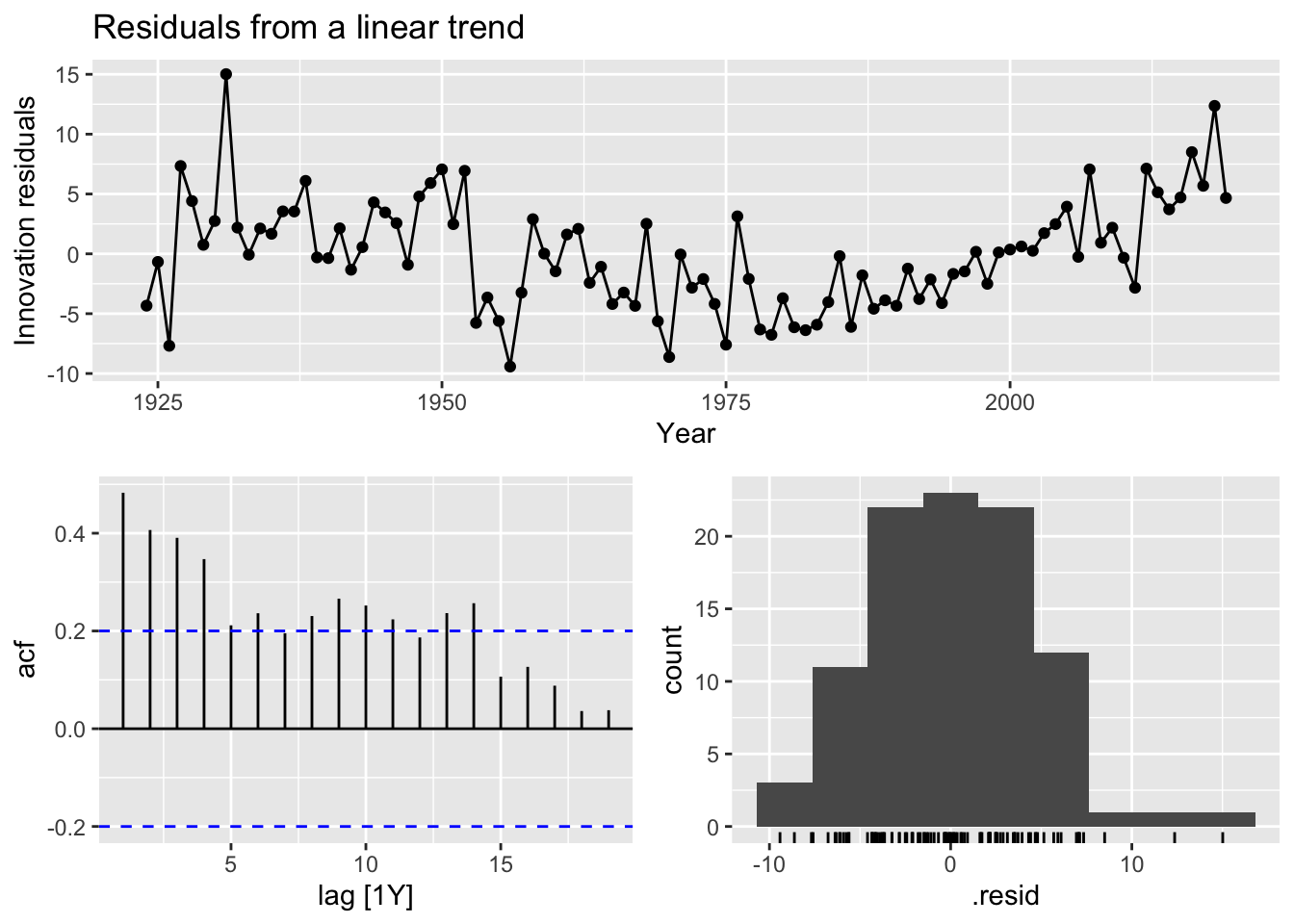
# exponential trend
fit_exp <- boston_men |>
model(TSLM(log(Minutes) ~ trend()))
fit_exp |>
augment() |>
autoplot(Minutes) +
geom_line(aes(y = .fitted), color = 'blue') +
labs(title = 'Boston marathon winning times (exp trend)')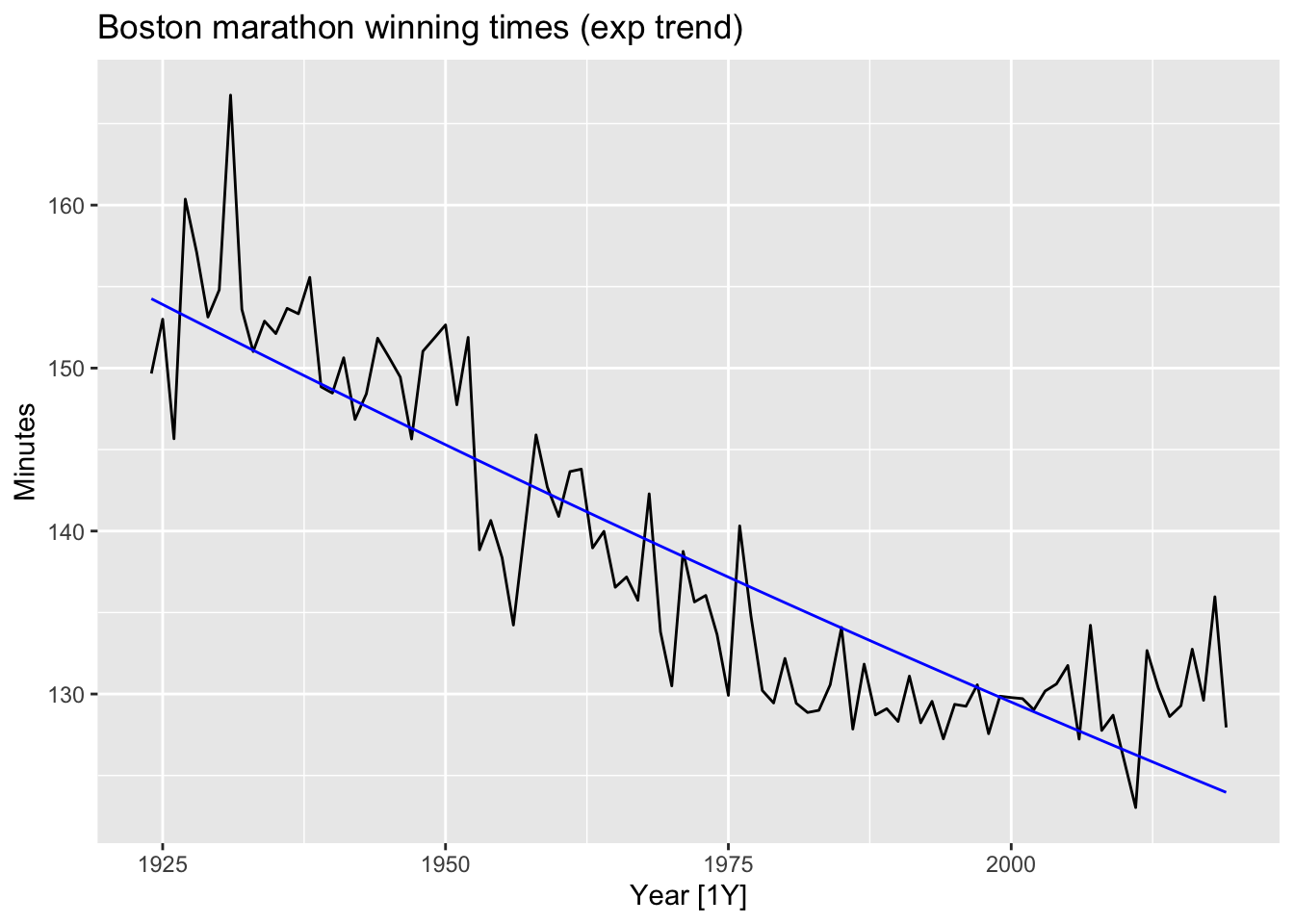
 ### Piacewise regression
### Piacewise regression
fit_trends <- boston_men |>
model(
linear = TSLM(Minutes ~ trend()),
exponential = TSLM(log(Minutes) ~ trend()),
piecewise = TSLM(Minutes ~ trend(knots = c(1950, 1980)))
)
fc_trends <- fit_trends |> forecast(h = 10)
boston_men |>
autoplot(Minutes) +
geom_line(data = fitted(fit_trends),
aes(y = .fitted, colour = .model)) +
autolayer(fc_trends, alpha = 0.5, level = 95) +
labs(y = "Minutes",
title = "Boston marathon winning times")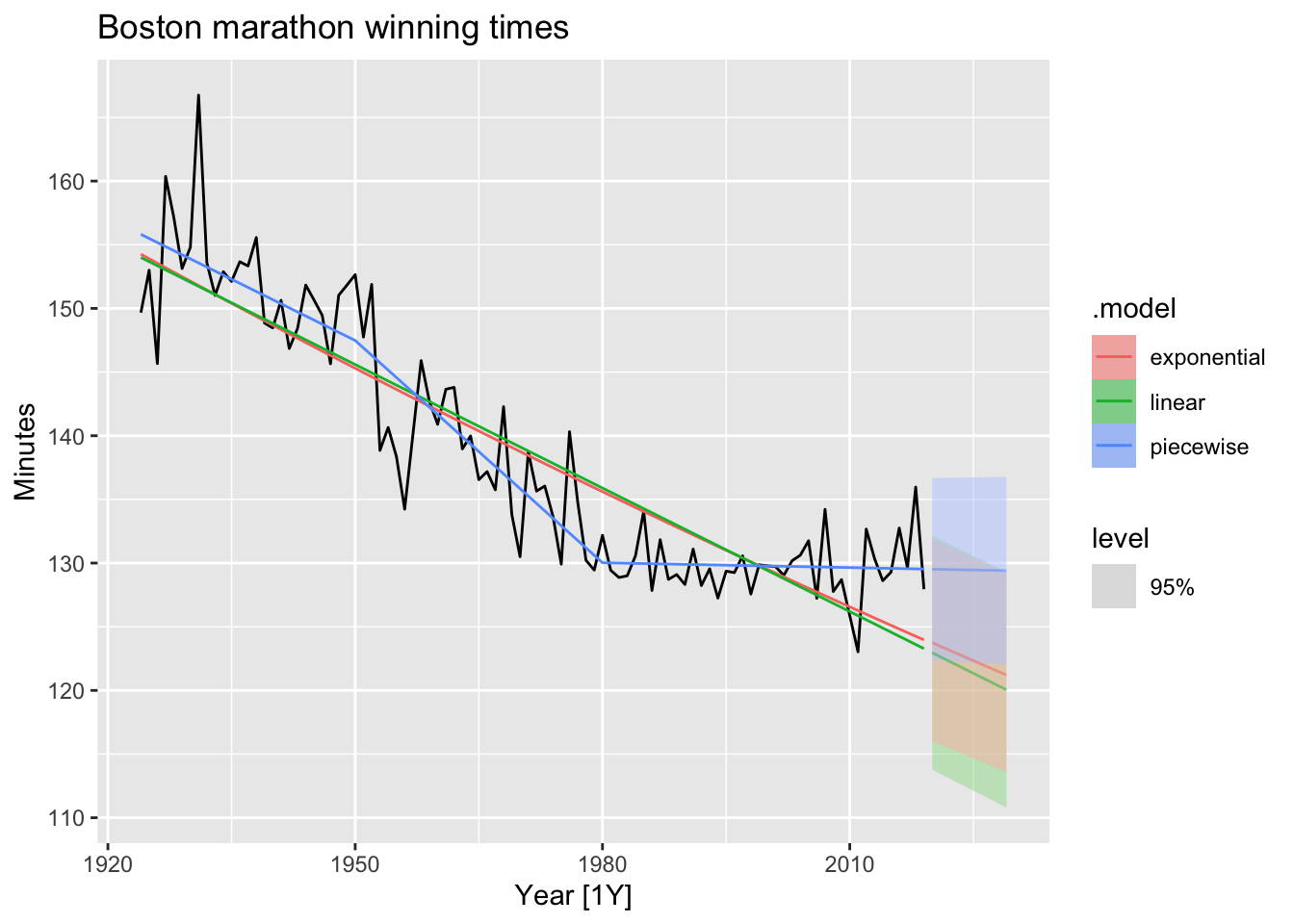
7.8 Correlation, causation and forecasting
7.8.1 Correlation is not causation
It is important not to confuse correlation with causation, or causation with forecasting. A variable \(x\) may be useful for forecasting a variable \(y\) , but that does not mean \(x\) is causing \(y\). It is possible that \(x\) is causing \(y\) , but it may be that \(y\) is causing \(x\) , or that the relationship between them is more complicated than simple causality.
7.8.3 Multicollinearity and forecasting
A closely related issue is multicollinearity, which occurs when similar information is provided by two or more of the predictor variables in a multiple regression.
An example of this problem is the dummy variable trap discussed in Section 7.4. Suppose you have quarterly data and use four dummy variables, \(d_1, d_2, d_3\) and \(d_4\). Then \(d_4 = 1 - d_1 - d_2 - d_3\), so there is perfect correlation between \(d_4\) and \(d_1 + d_2 + d_3\).
Note! If you are using good statistical software, if you are not interested in the specific contributions of each predictor, and if the future values of your predictor variables are within their historical ranges, there is nothing to worry about — multicollinearity is not a problem except when there is perfect correlation.
7.9 Exercises
jan14_victoria_elec <- vic_elec |>
filter(yearmonth(Time) == yearmonth('2014 Jan')) |>
index_by(Date = as_date(Time)) |>
summarise(Demand = sum(Demand),
Temperature = max(Temperature))
jan14_victoria_elec## # A tsibble: 31 x 3 [1D]
## Date Demand Temperature
## <date> <dbl> <dbl>
## 1 2014-01-01 175185. 26
## 2 2014-01-02 188351. 23
## 3 2014-01-03 189086. 22.2
## 4 2014-01-04 173798. 20.3
## 5 2014-01-05 169733. 26.1
## 6 2014-01-06 195241. 19.6
## 7 2014-01-07 199770. 20
## 8 2014-01-08 205339. 27.4
## 9 2014-01-09 227334. 32.4
## 10 2014-01-10 258111. 34
## # ℹ 21 more rows# a.
jan14_victoria_elec |>
autoplot(Demand) +
labs(title = 'Electricity demand on 2014 Jan', y = 'MWh')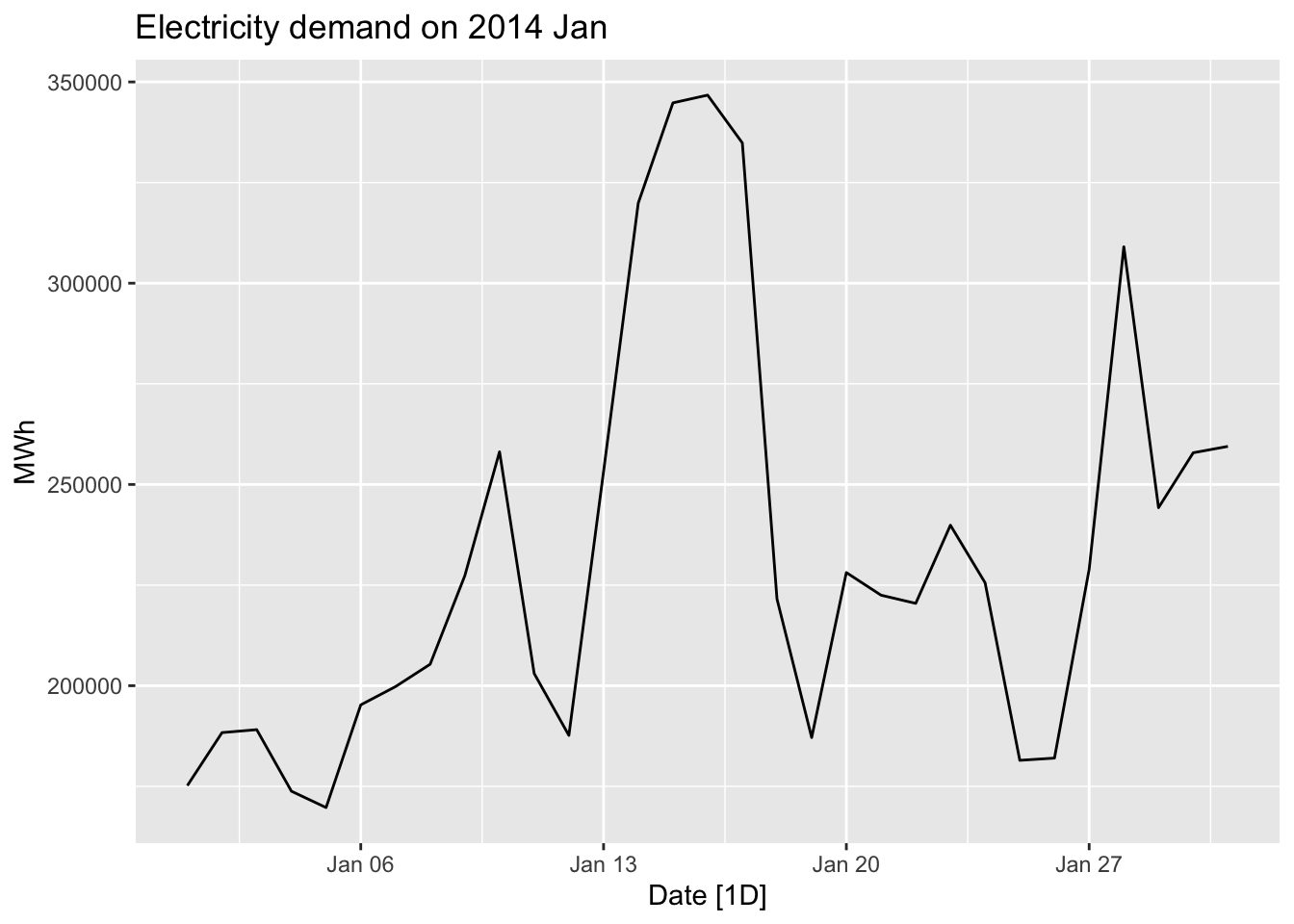
## Series: Demand
## Model: TSLM
##
## Residuals:
## Min 1Q Median 3Q Max
## -49978.2 -10218.9 -121.3 18533.2 35440.6
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 59083.9 17424.8 3.391 0.00203 **
## Temperature 6154.3 601.3 10.235 3.89e-11 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 24540 on 29 degrees of freedom
## Multiple R-squared: 0.7832, Adjusted R-squared: 0.7757
## F-statistic: 104.7 on 1 and 29 DF, p-value: 3.8897e-11jan14_victoria_elec |>
ggplot(aes(x=Temperature, y = Demand)) +
geom_point() +
geom_smooth(method = 'lm', se = FALSE) +
labs(title = 'Relationship between temperature and electricity demand',
y = 'Demand, MWh', x = 'Temperature, C')## `geom_smooth()` using formula = 'y ~ x'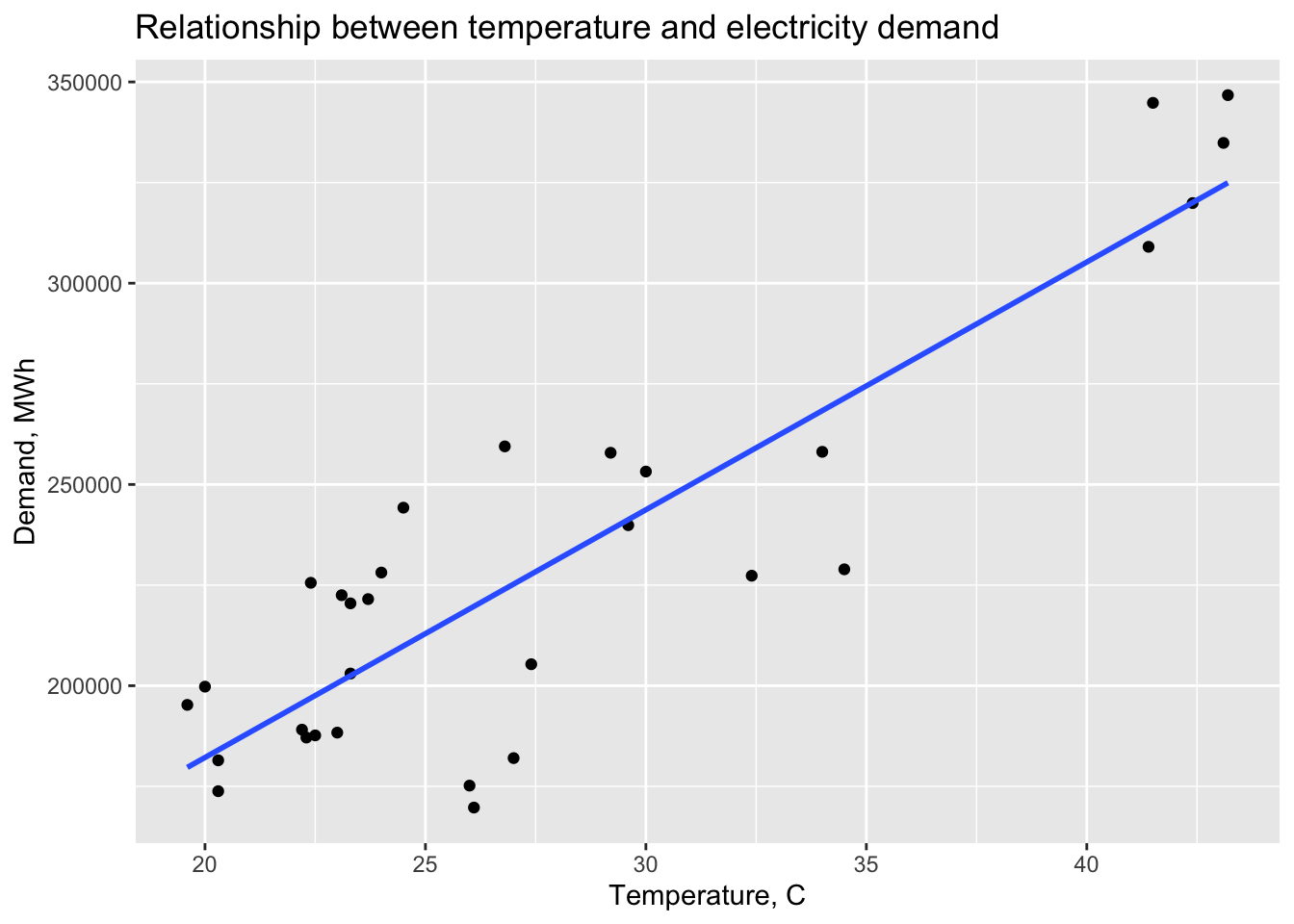
January is a summer month in Australia, the more temperature outside was the more air conditioning is used inside.
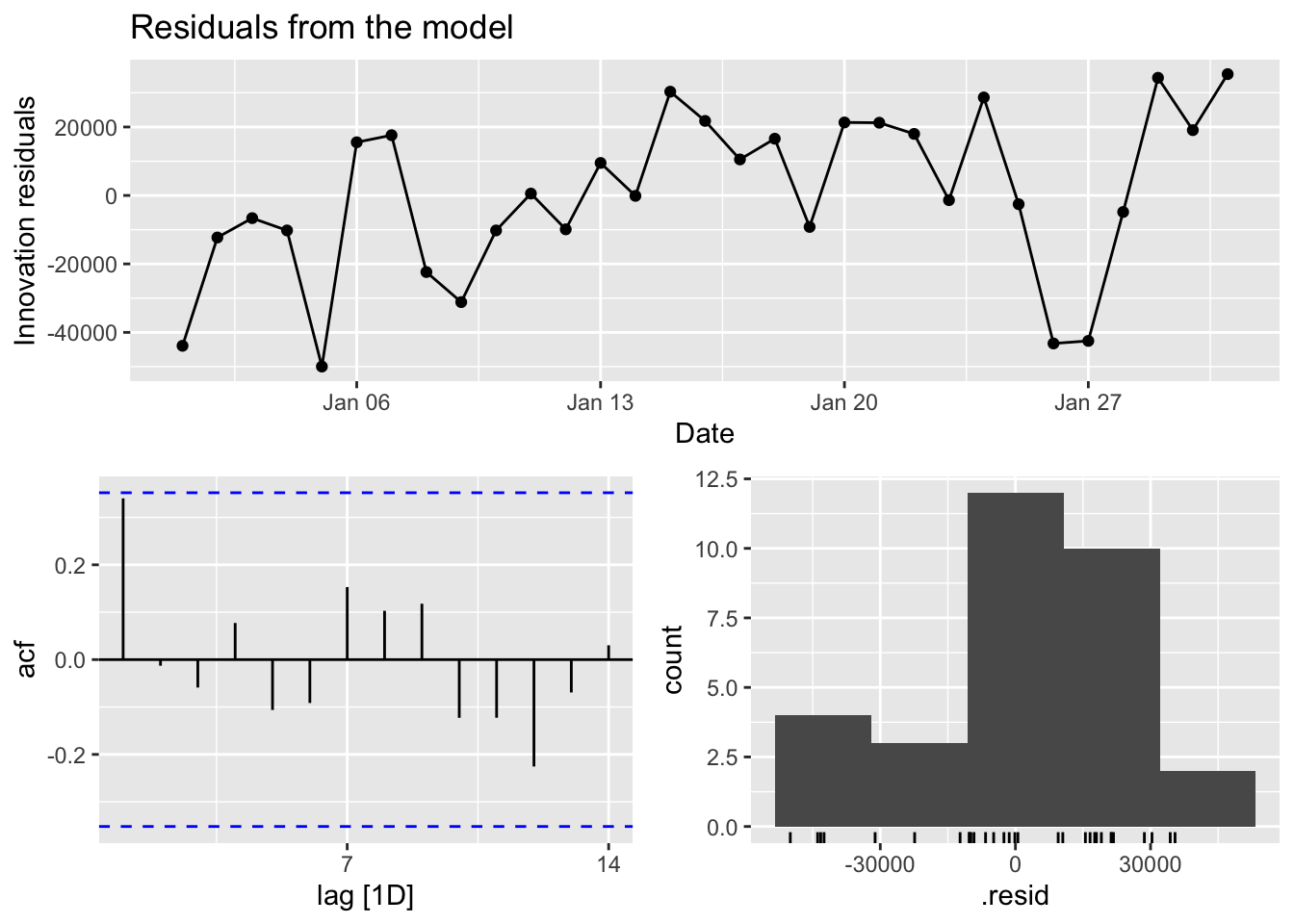
# c.
fc <- fit_elec |>
forecast(
new_data = scenarios(
'max15' = new_data(jan14_victoria_elec, 1) |> mutate(Temperature = 15),
'max35' = new_data(jan14_victoria_elec, 1) |> mutate(Temperature = 35), names_to = 'Scenarios')
)
jan14_victoria_elec |>
autoplot(Demand) +
autolayer(fc)## Warning: Computation failed in `stat_interval()`.
## Caused by error in `trans$transform()`:
## ! `transform_date()` works with objects of class <Date> only## Warning in min(x, na.rm = na.rm): no non-missing arguments to min; returning Inf## Warning in max(x, na.rm = na.rm): no non-missing arguments to max; returning -Inf## Warning in min(x, na.rm = na.rm): no non-missing arguments to min; returning Inf## Warning in max(x, na.rm = na.rm): no non-missing arguments to max; returning -Inf## Warning in min(x, na.rm = na.rm): no non-missing arguments to min; returning Inf## Warning in max(x, na.rm = na.rm): no non-missing arguments to max; returning -Inf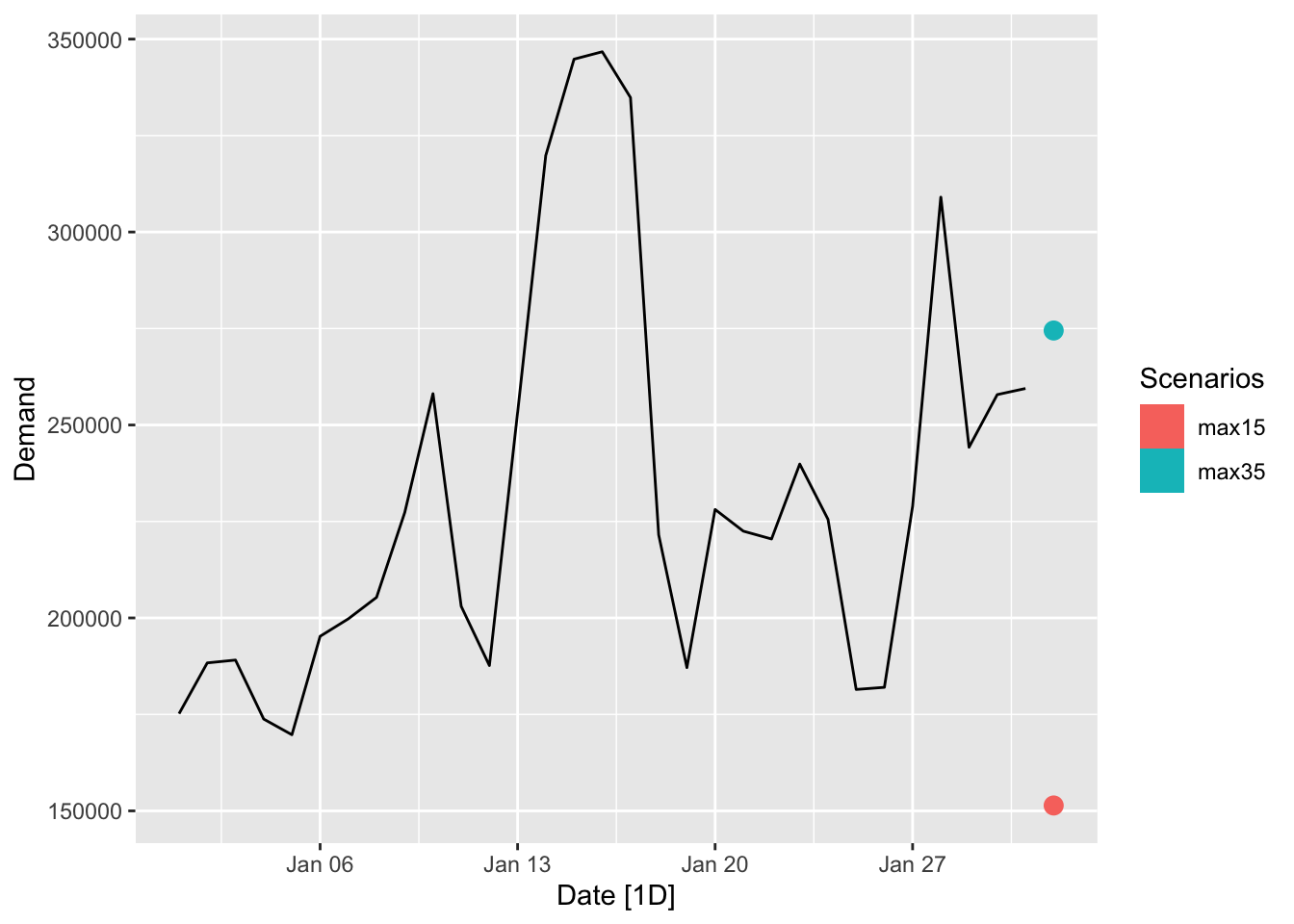
# d.
fc <- fit_elec |>
forecast(
new_data = scenarios(
'max15' = new_data(jan14_victoria_elec, 2) |> mutate(Temperature = 15),
'max35' = new_data(jan14_victoria_elec, 2) |> mutate(Temperature = 35), names_to = 'Scenarios')
)
jan14_victoria_elec |>
autoplot(Demand) +
autolayer(fc)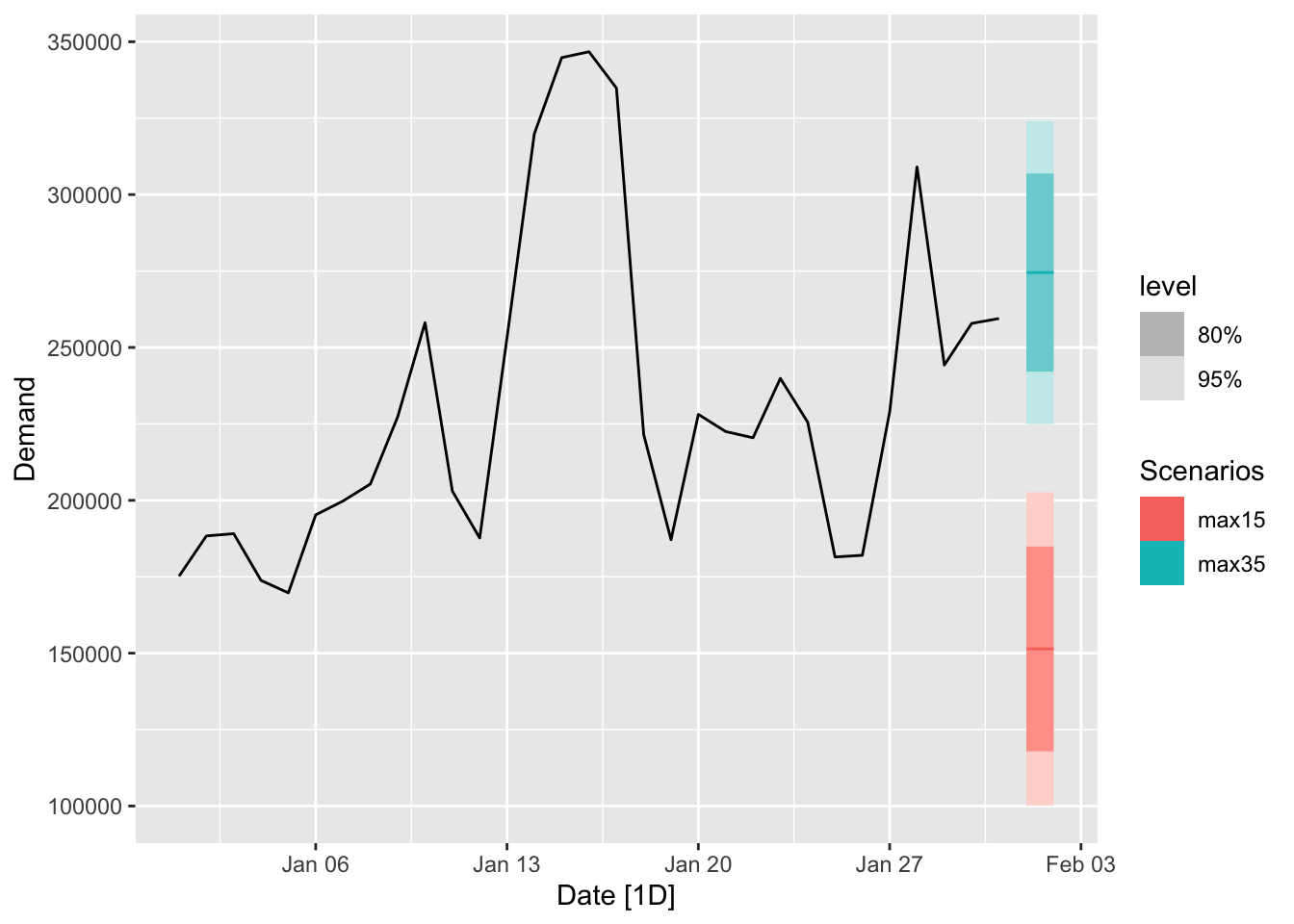
# e.
vic_elec |>
index_by(Date = as_date(Time)) |>
summarise(
Demand = sum(Demand),
Temperature = max(Temperature)
) |>
ggplot(aes(x = Temperature, y = Demand)) +
geom_point()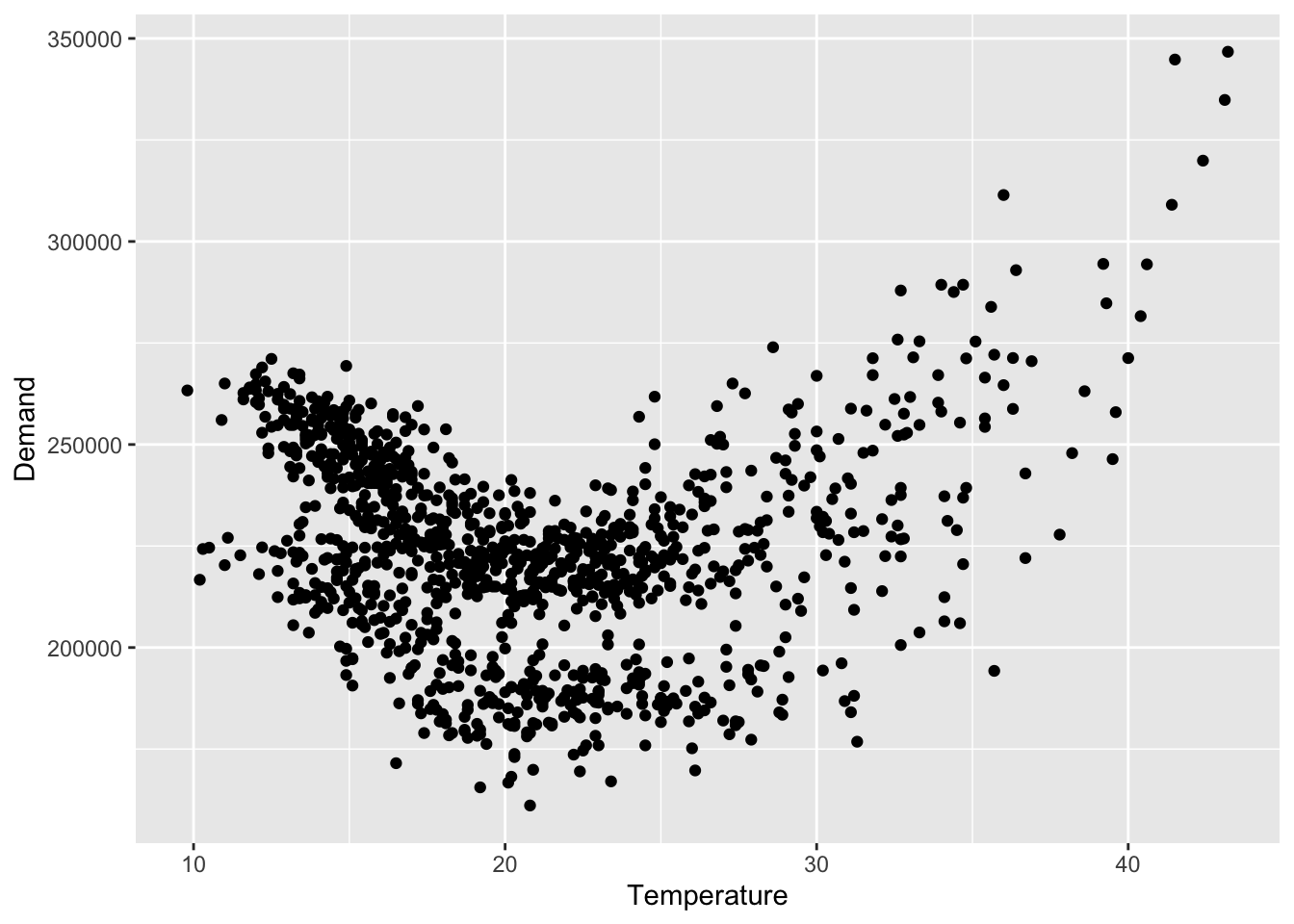
The Temperature and the Demand do not have linear relationship, so the linear model might not be the best choice.
# a.
olympic_running |>
autoplot(Time) +
facet_grid(Length ~ Sex, scales = 'free_y') +
theme(legend.position = 'none')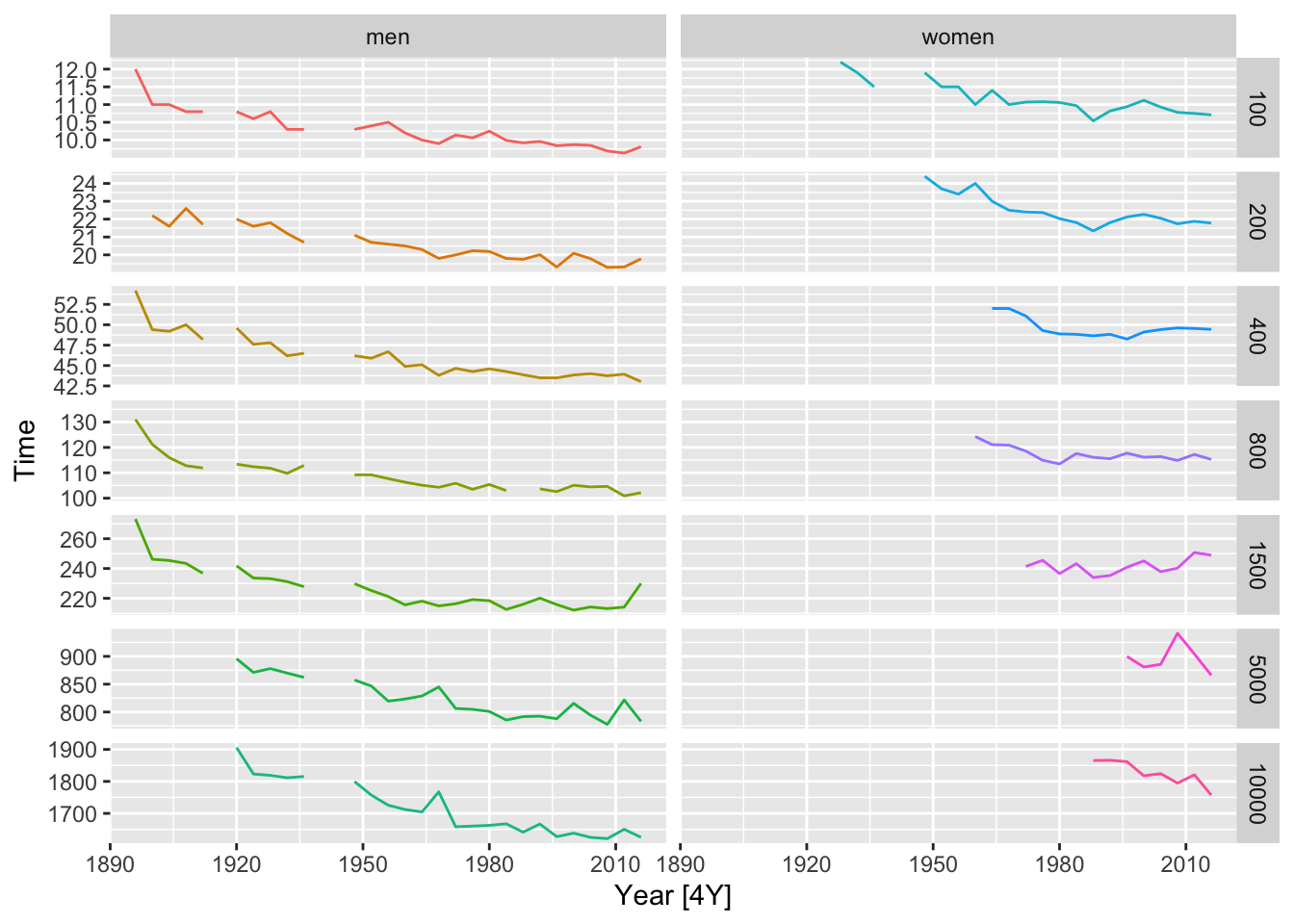
# b.
fit <- olympic_running |>
model(TSLM(Time ~ trend()))
aug <- fit |> augment()
# get the regression lines
olympic_running |>
autoplot(Time) +
autolayer(aug, .fitted) +
facet_grid(Length ~ Sex, scales = 'free_y') +
theme(legend.position = 'none')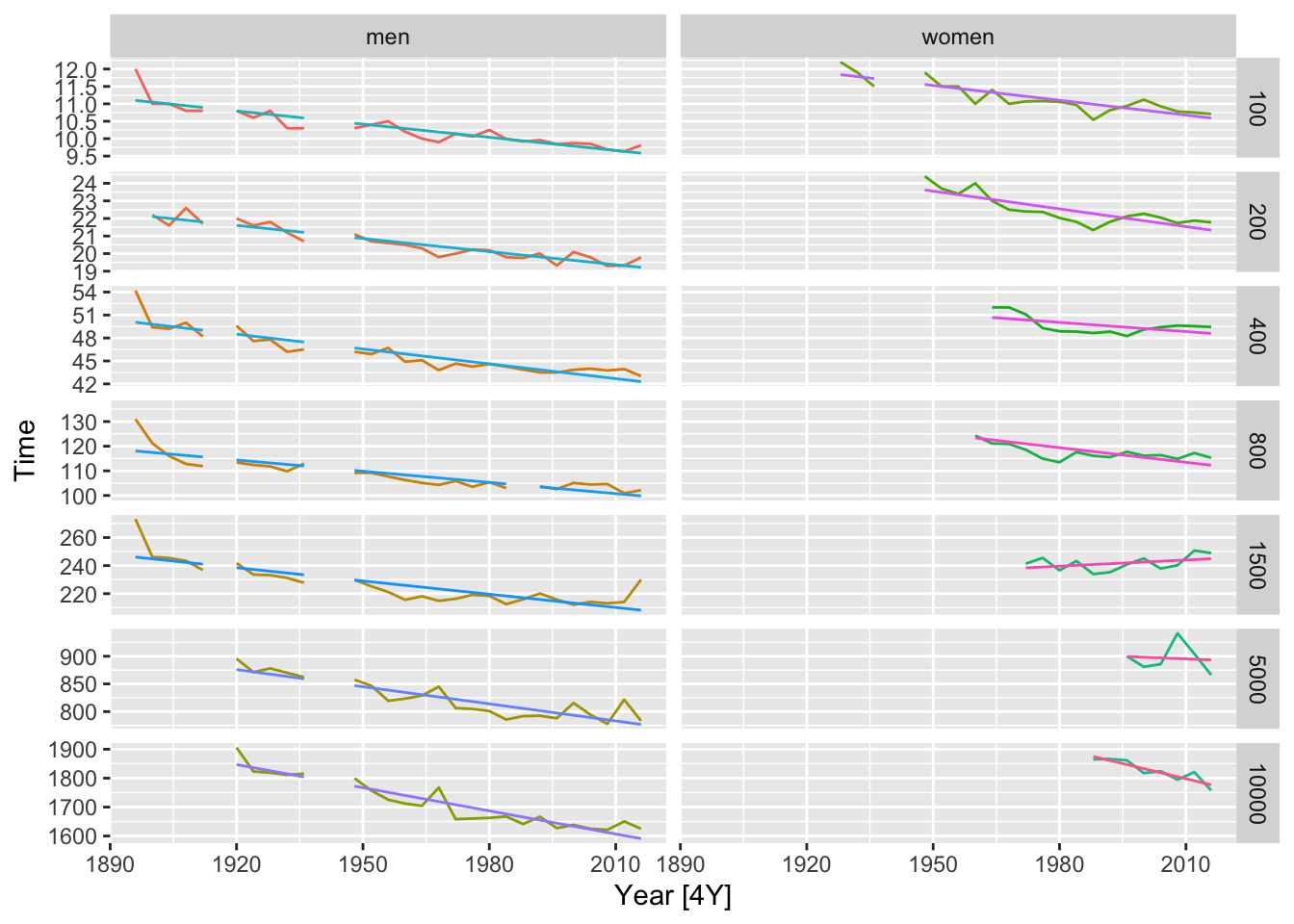
# get average rate per year
fit |>
tidy() |>
filter(term == 'trend()') |>
select(Length, Sex, `Average rate per year`=estimate)## # A tibble: 14 × 3
## Length Sex `Average rate per year`
## <int> <chr> <dbl>
## 1 100 men -0.0504
## 2 100 women -0.0567
## 3 200 men -0.0995
## 4 200 women -0.135
## 5 400 men -0.258
## 6 400 women -0.160
## 7 800 men -0.607
## 8 800 women -0.792
## 9 1500 men -1.26
## 10 1500 women 0.587
## 11 5000 men -4.12
## 12 5000 women -1.21
## 13 10000 men -10.7
## 14 10000 women -14.0# c.
# prot the residuals vs year
fit |>
augment() |>
ggplot(aes(x = Year, y = .resid)) +
geom_line() +
facet_grid(Length ~ Sex, scales = 'free_y')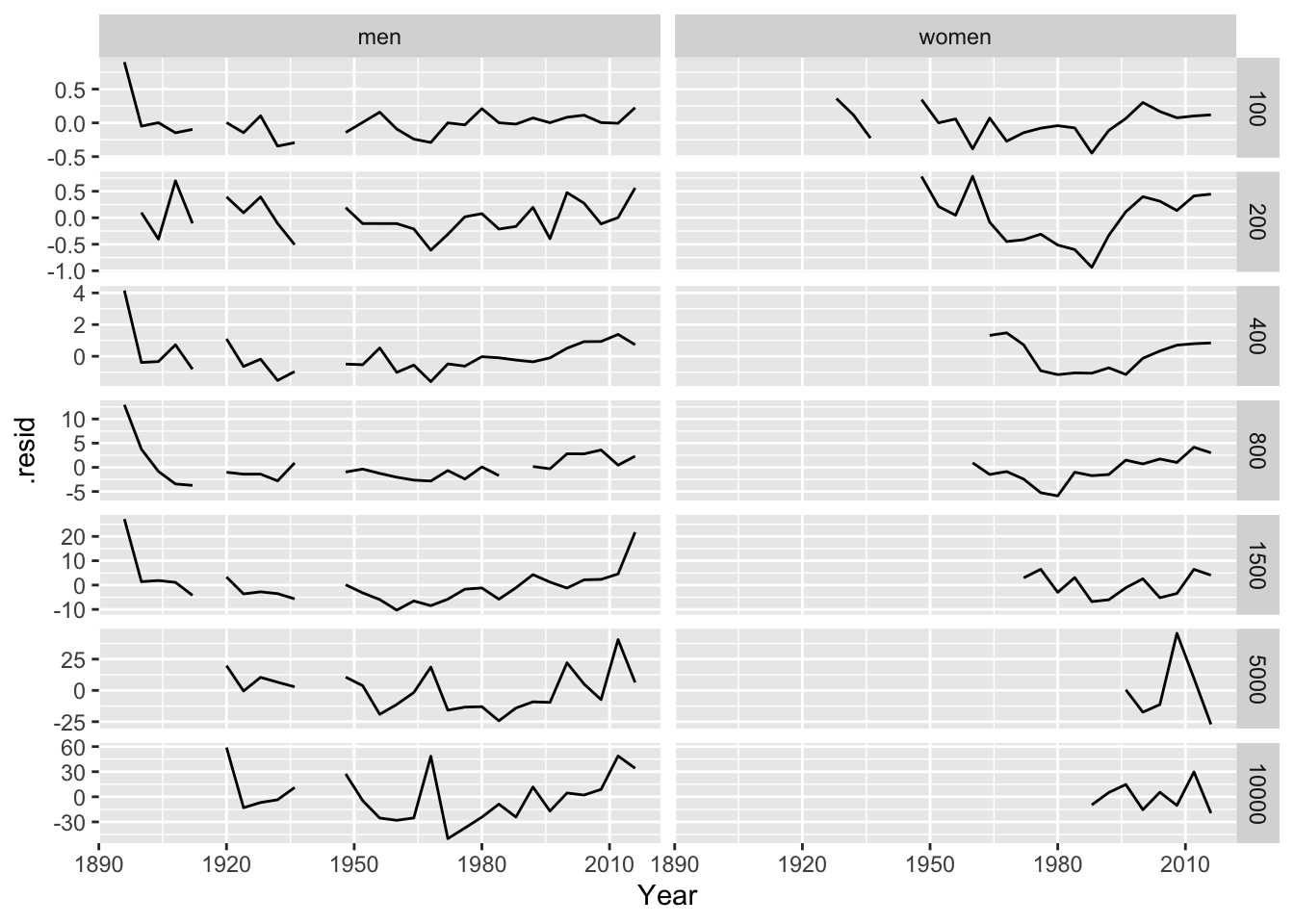
# d.
olympic_running |>
autoplot(Time) +
autolayer(fit |>
forecast(h=2)
) +
facet_grid(Length ~ Sex, scales = 'free_y') +
theme(legend.position = 'none')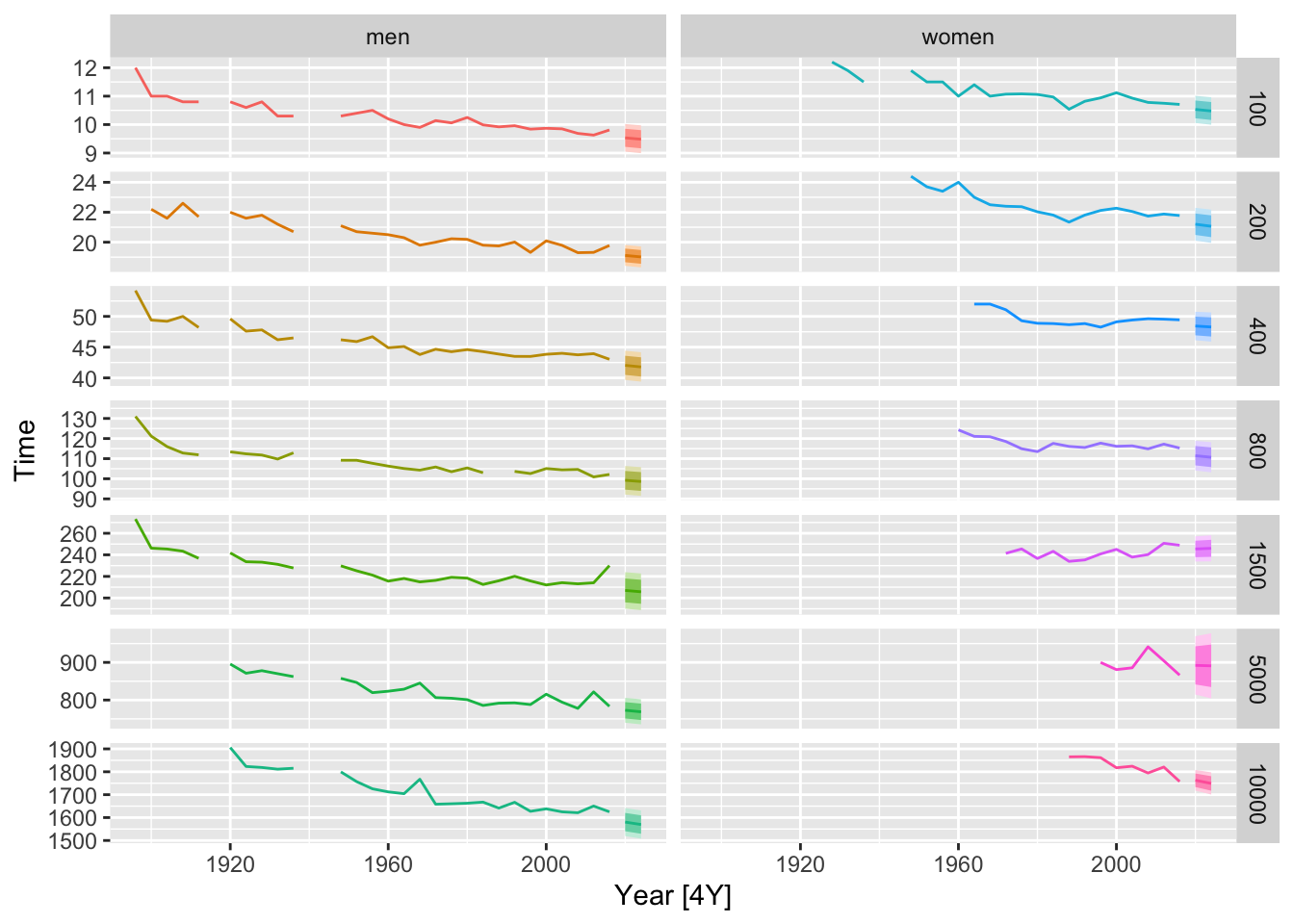
## # A tsibble: 84 x 2 [1M]
## Month Sales
## <mth> <dbl>
## 1 1987 Jan 1665.
## 2 1987 Feb 2398.
## 3 1987 Mar 2841.
## 4 1987 Apr 3547.
## 5 1987 May 3753.
## 6 1987 Jun 3715.
## 7 1987 Jul 4350.
## 8 1987 Aug 3566.
## 9 1987 Sep 5022.
## 10 1987 Oct 6423.
## # ℹ 74 more rows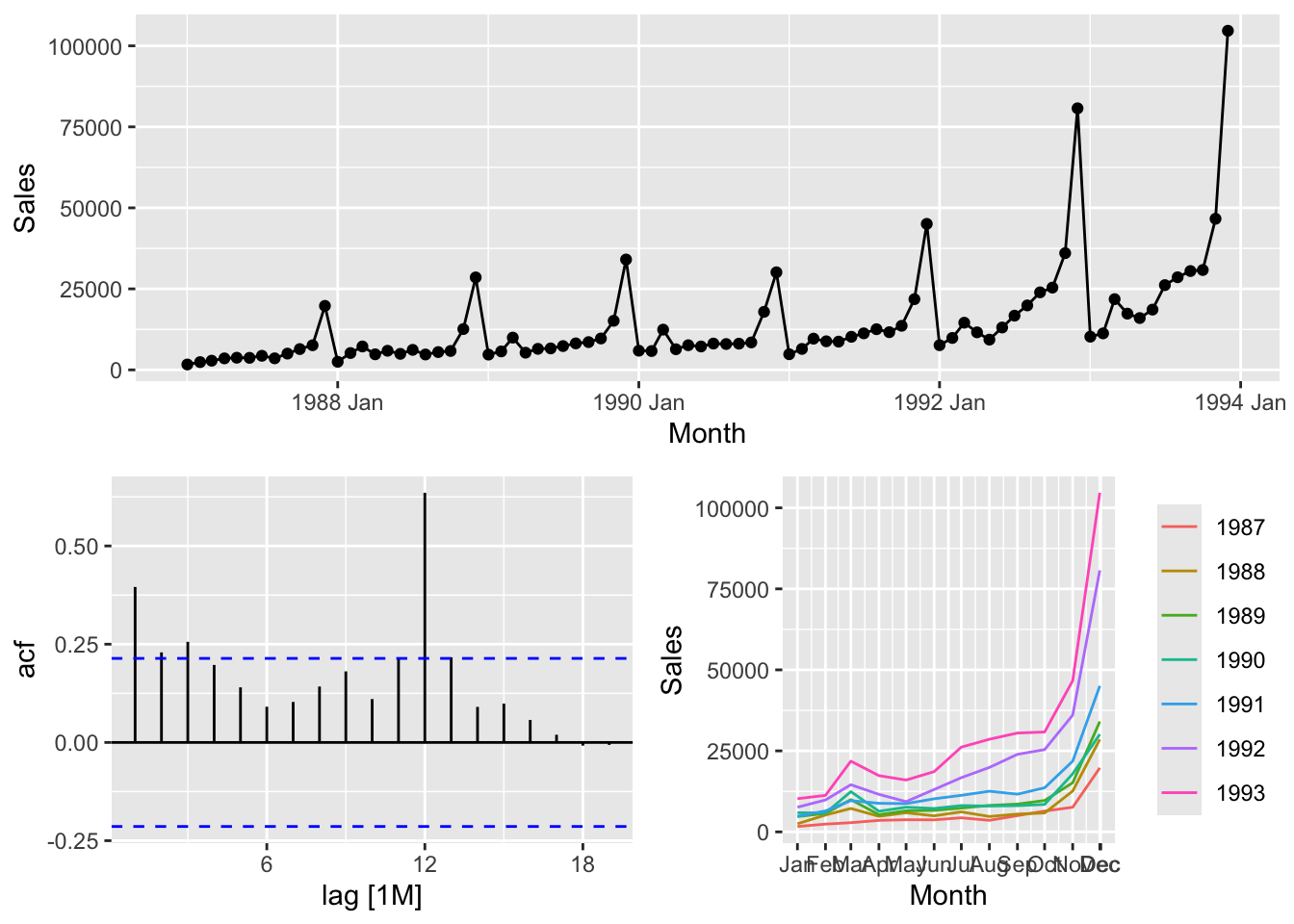
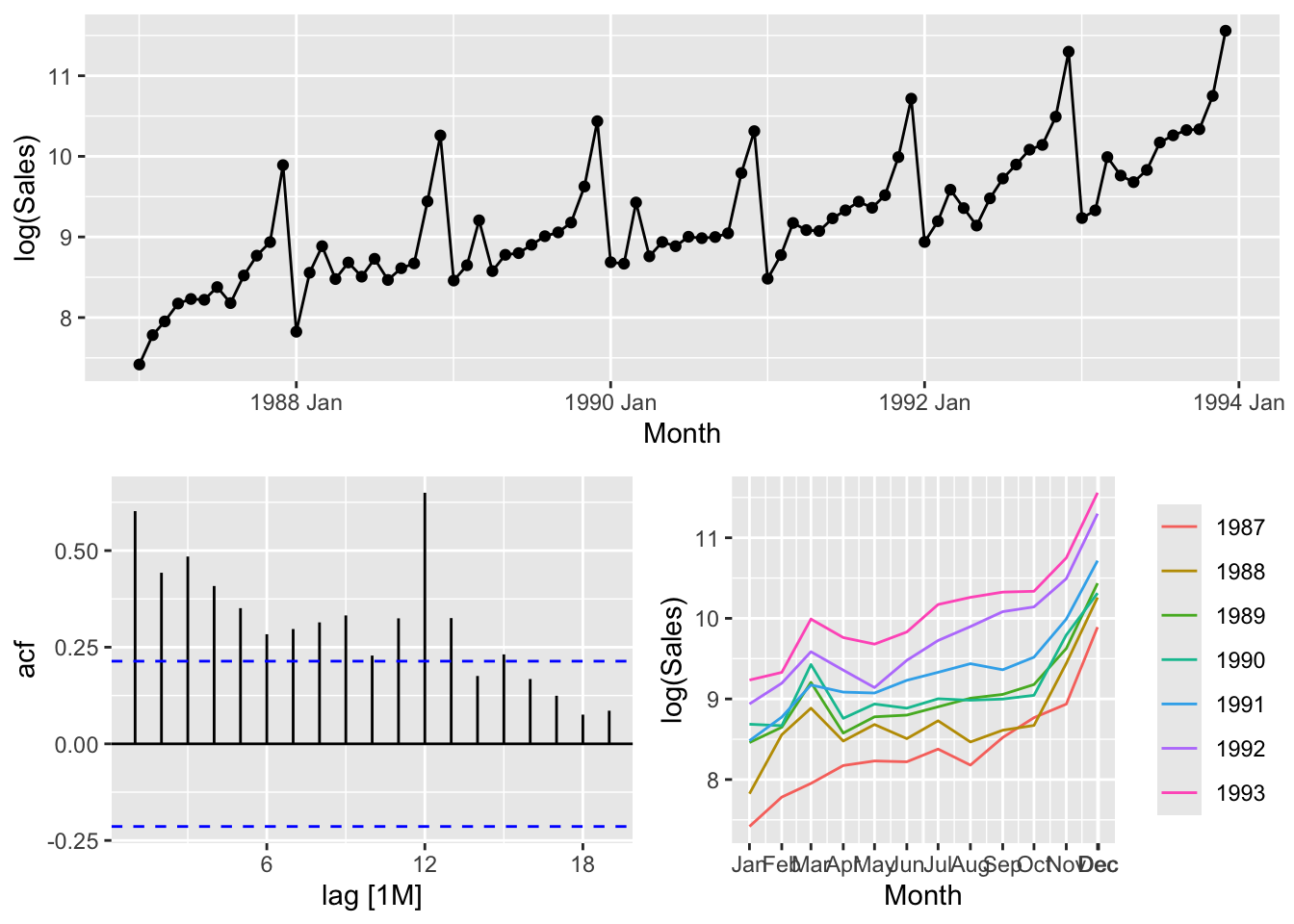
# Because of the fluctuation of the variance the logarithms should be applied
# to make stationary time series.# c.
souvenirs_log <- souvenirs |>
mutate(Sales_log = log(Sales),
`Surfing Festival` = ifelse(year(Month) >= 1988 &
month(Month) == 3, 1, 0))
fit <- souvenirs_log |>
model(TSLM(Sales_log ~ trend() + season() + `Surfing Festival`))# d.
fit |>
augment() |>
ggplot(aes(x = Month, y = .resid)) +
geom_point() +
labs(title = 'Residuals vs Time')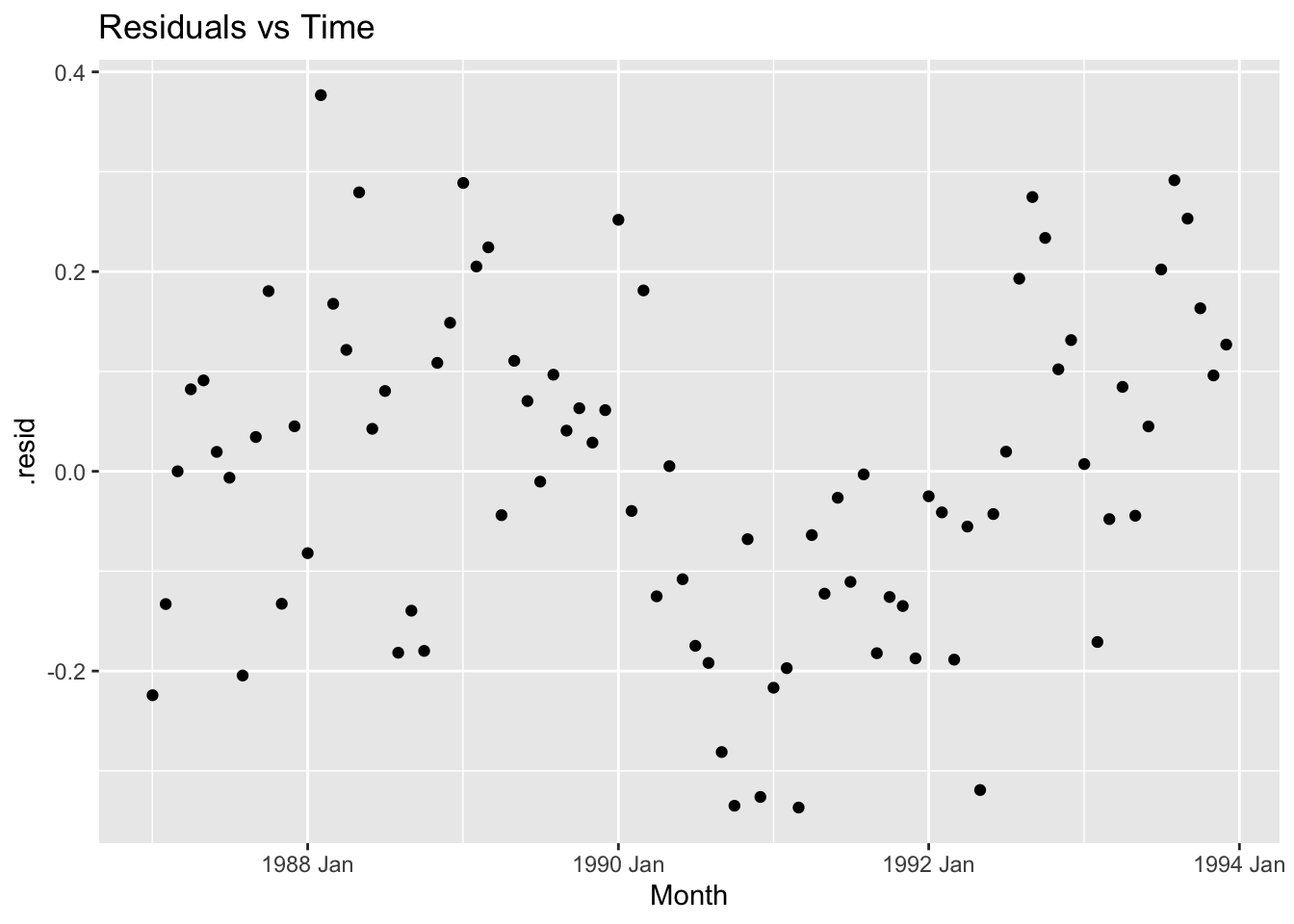
fit |>
augment() |>
ggplot(aes(x = .fitted, y = .resid)) +
geom_point() +
labs(title = 'Residuals vs Fitted')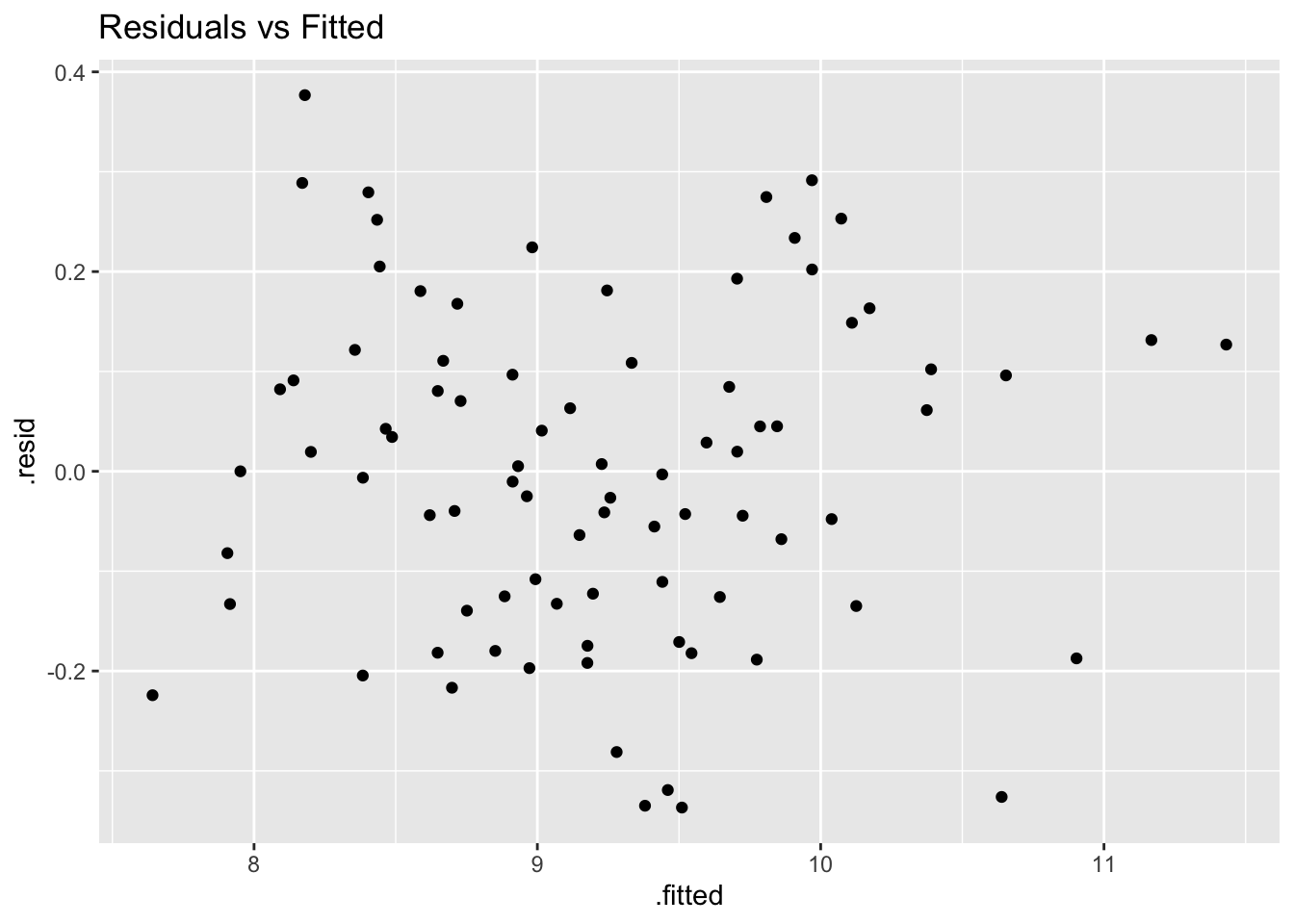
# e.
fit |>
augment() |>
ggplot(aes(x = factor(month(Month)), y = .resid)) +
geom_boxplot() +
labs(title = 'Box plot per Month')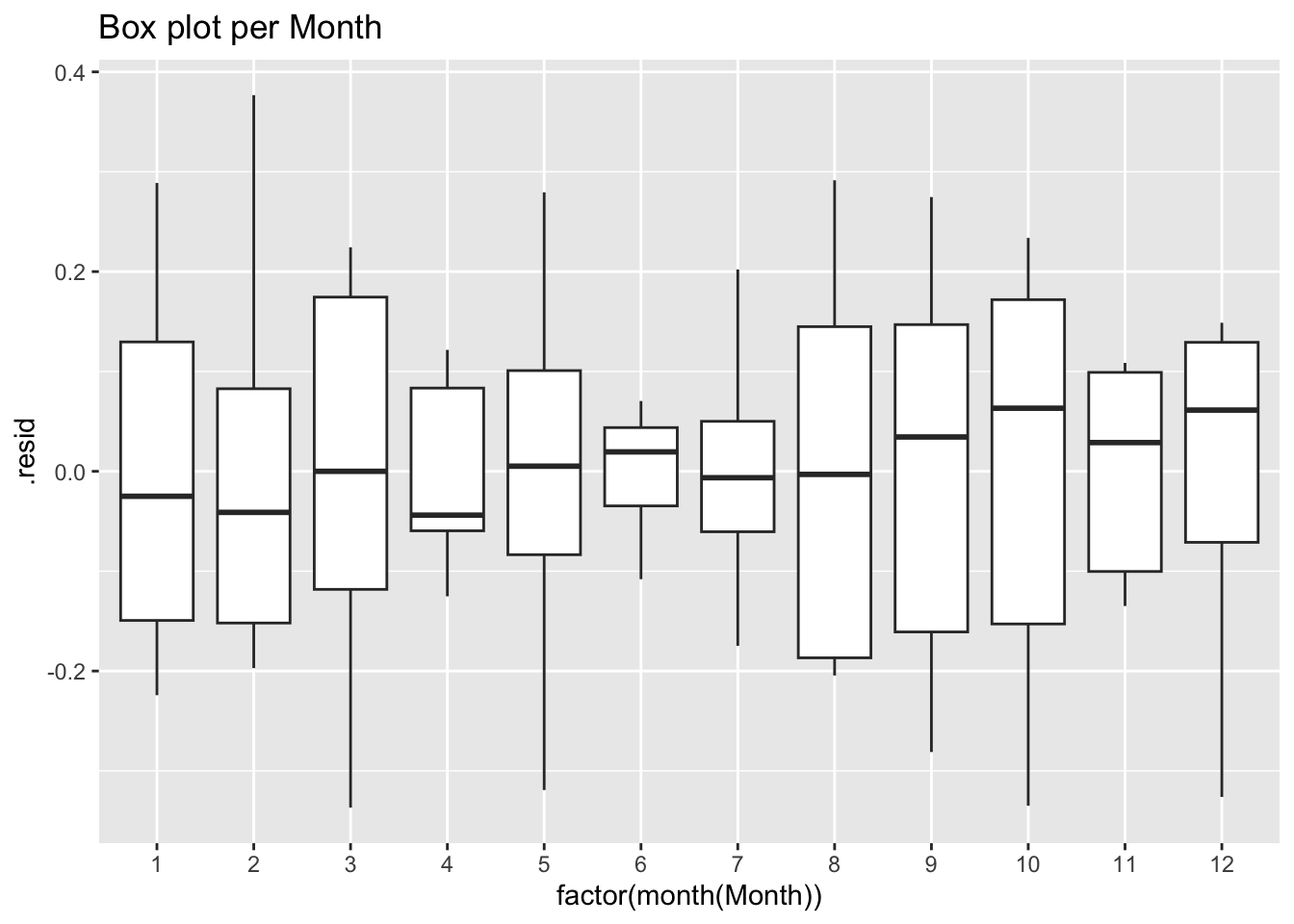
## Series: Sales_log
## Model: TSLM
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.336727 -0.127571 0.002568 0.109106 0.376714
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.6196670 0.0742471 102.626 < 2e-16 ***
## trend() 0.0220198 0.0008268 26.634 < 2e-16 ***
## season()year2 0.2514168 0.0956790 2.628 0.010555 *
## season()year3 0.2660828 0.1934044 1.376 0.173275
## season()year4 0.3840535 0.0957075 4.013 0.000148 ***
## season()year5 0.4094870 0.0957325 4.277 5.88e-05 ***
## season()year6 0.4488283 0.0957647 4.687 1.33e-05 ***
## season()year7 0.6104545 0.0958039 6.372 1.71e-08 ***
## season()year8 0.5879644 0.0958503 6.134 4.53e-08 ***
## season()year9 0.6693299 0.0959037 6.979 1.36e-09 ***
## season()year10 0.7473919 0.0959643 7.788 4.48e-11 ***
## season()year11 1.2067479 0.0960319 12.566 < 2e-16 ***
## season()year12 1.9622412 0.0961066 20.417 < 2e-16 ***
## `Surfing Festival` 0.5015151 0.1964273 2.553 0.012856 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.179 on 70 degrees of freedom
## Multiple R-squared: 0.9567, Adjusted R-squared: 0.9487
## F-statistic: 119 on 13 and 70 DF, p-value: < 2.22e-16## # A tibble: 1 × 3
## .model lb_stat lb_pvalue
## <chr> <dbl> <dbl>
## 1 TSLM(Sales_log ~ trend() + season() + `Surfing Festival`) 76.9 1.63e-11# h.
fc <- fit |>
forecast(new_data = scenarios(new_data(souvenirs, 12) |>
mutate(`Surfing Festival` = ifelse(month(Month) == 3, 1, 0)),
new_data(souvenirs, 24) |>
mutate(`Surfing Festival` = ifelse(month(Month) == 3, 1, 0)),
new_data(souvenirs, 36) |>
mutate(`Surfing Festival` = ifelse(month(Month) == 3, 1, 0))))
souvenirs_log |>
autoplot(Sales_log) +
autolayer(fc |> mutate(.scenario = factor(.scenario))) +
facet_grid(.scenario ~ ., scales = 'free_y')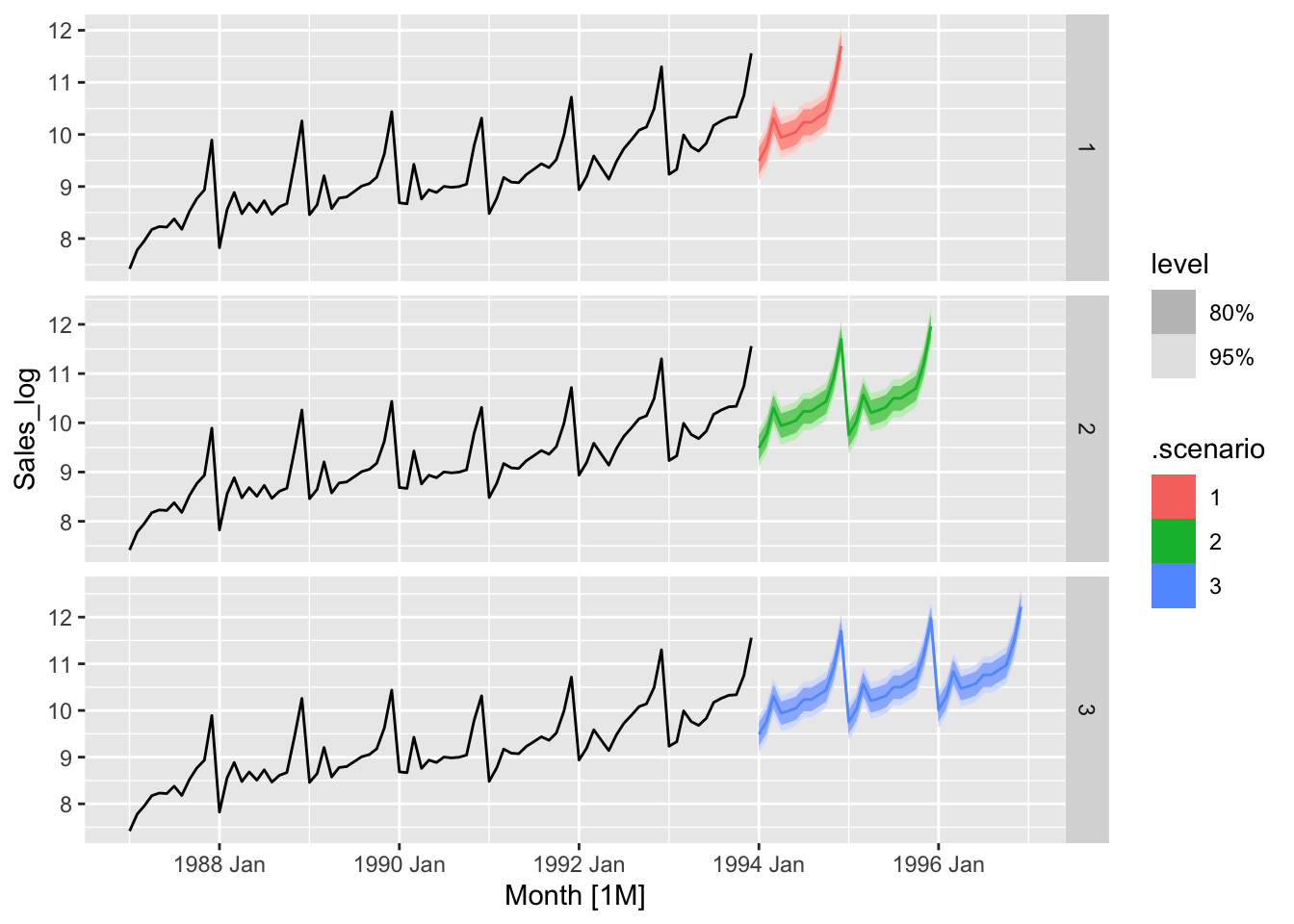
gasoline <- us_gasoline |>
filter(year(Week) <= 2004)
gasoline |>
autoplot(Barrels) +
labs(y = 'Million barrels per day',
title = 'Weekly data for supplies of US finished motor gasoline product')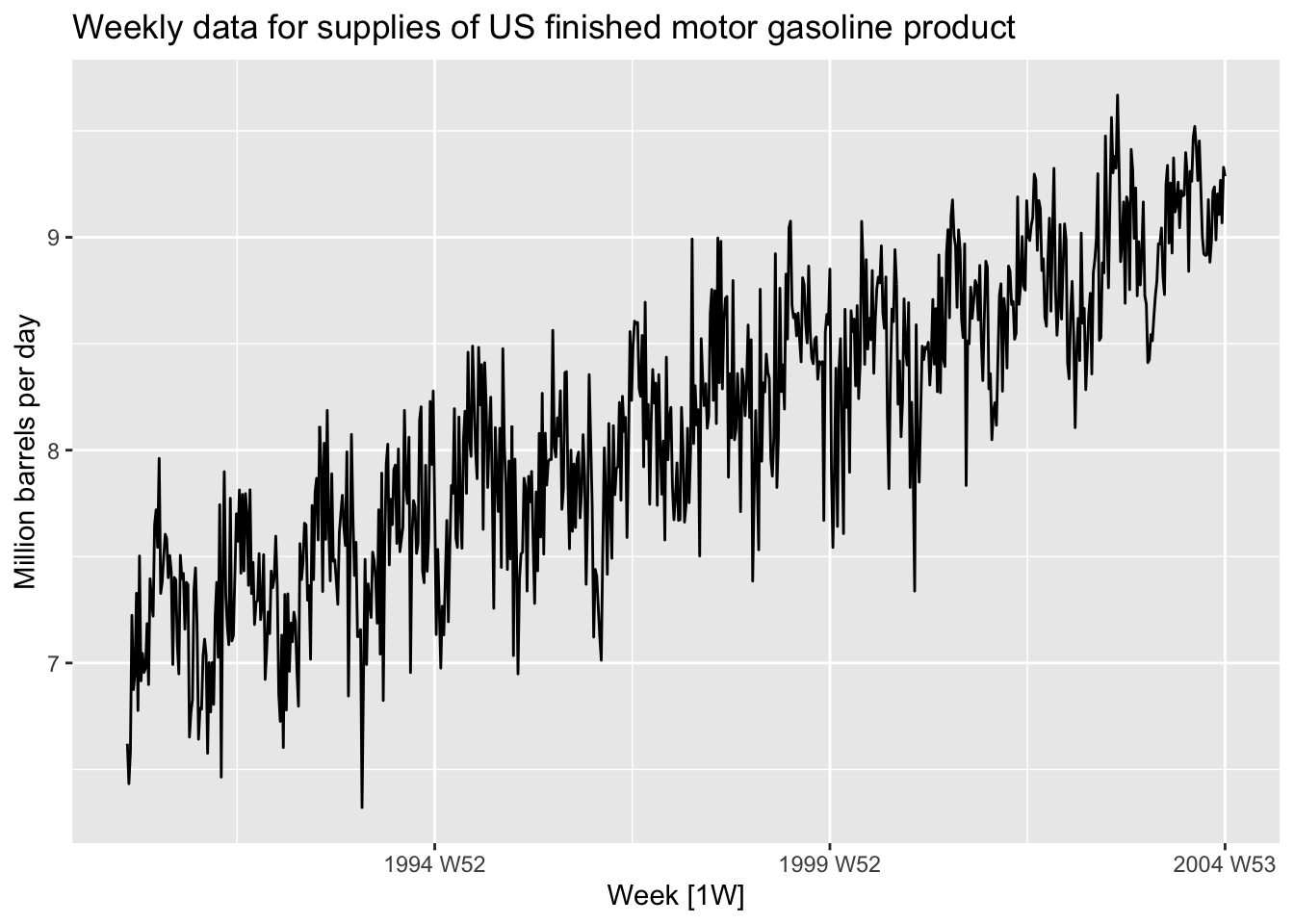
plots <- list()
fits <- list()
minACCc = 10000
for (i in seq(52/2)) {
fit <- gasoline |>
model(TSLM(Barrels ~ trend() + fourier(K=i)))
fits[[i]] <- fit # keep fit
AICc <- round(glance(fit)[['AICc']], 2)
if(AICc < minACCc){
minACCc <- AICc
}
plots[[i]] <- fit |>
augment() |>
ggplot(aes(x = Week, y = Barrels)) +
geom_line(aes(color = 'Actual Data')) +
geom_line(aes(y = .fitted, color = 'Fitted')) +
theme(legend.position = 'none') +
scale_color_manual(values = c('Actual Data'='darkgray', 'Fitted'='red')) +
xlab(paste("K=", i, " AICc=", AICc))
}
do.call(gridExtra::grid.arrange, c(plots, ncol = 1))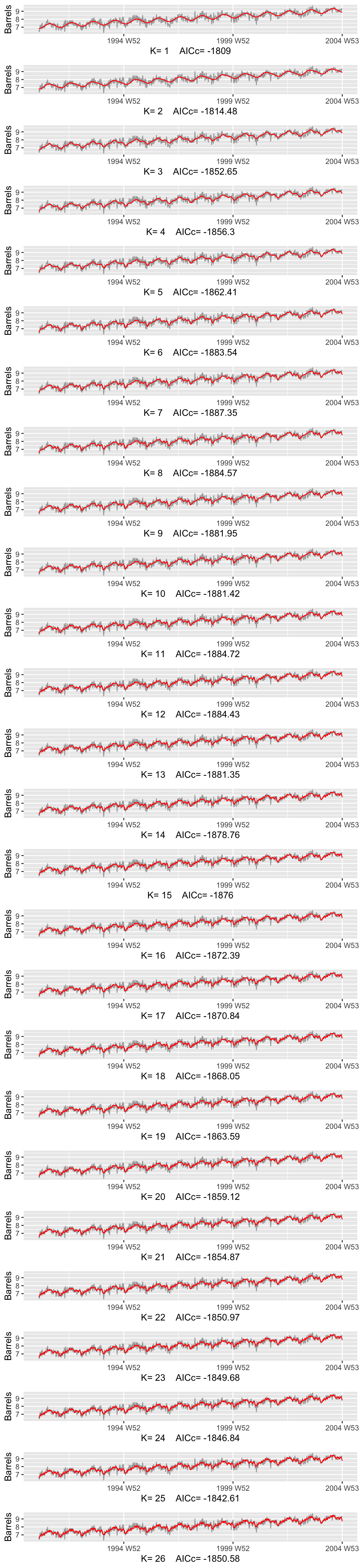
# b.
K = which.min(sapply(fits, function(fit) {
round(glance(fit)[['AICc']], 2)
}))
print(paste('Optimal K =', K, ', AICc = ', round(glance(fits[[K]])[['AICc']], 2)))## [1] "Optimal K = 7 , AICc = -1887.35"fits[[K]] |>
augment() |>
ggplot(aes(x = Week, y = Barrels)) +
geom_line(aes(color = 'Actual Data')) +
geom_line(aes(y = .fitted, color = 'Fitted')) +
theme(legend.position = 'none') +
scale_color_manual(values = c('Actual Data'='darkgray', 'Fitted'='red')) +
xlab(paste("K=", K, " AICc=", round(glance(fits[[K]])[['AICc']], 2)))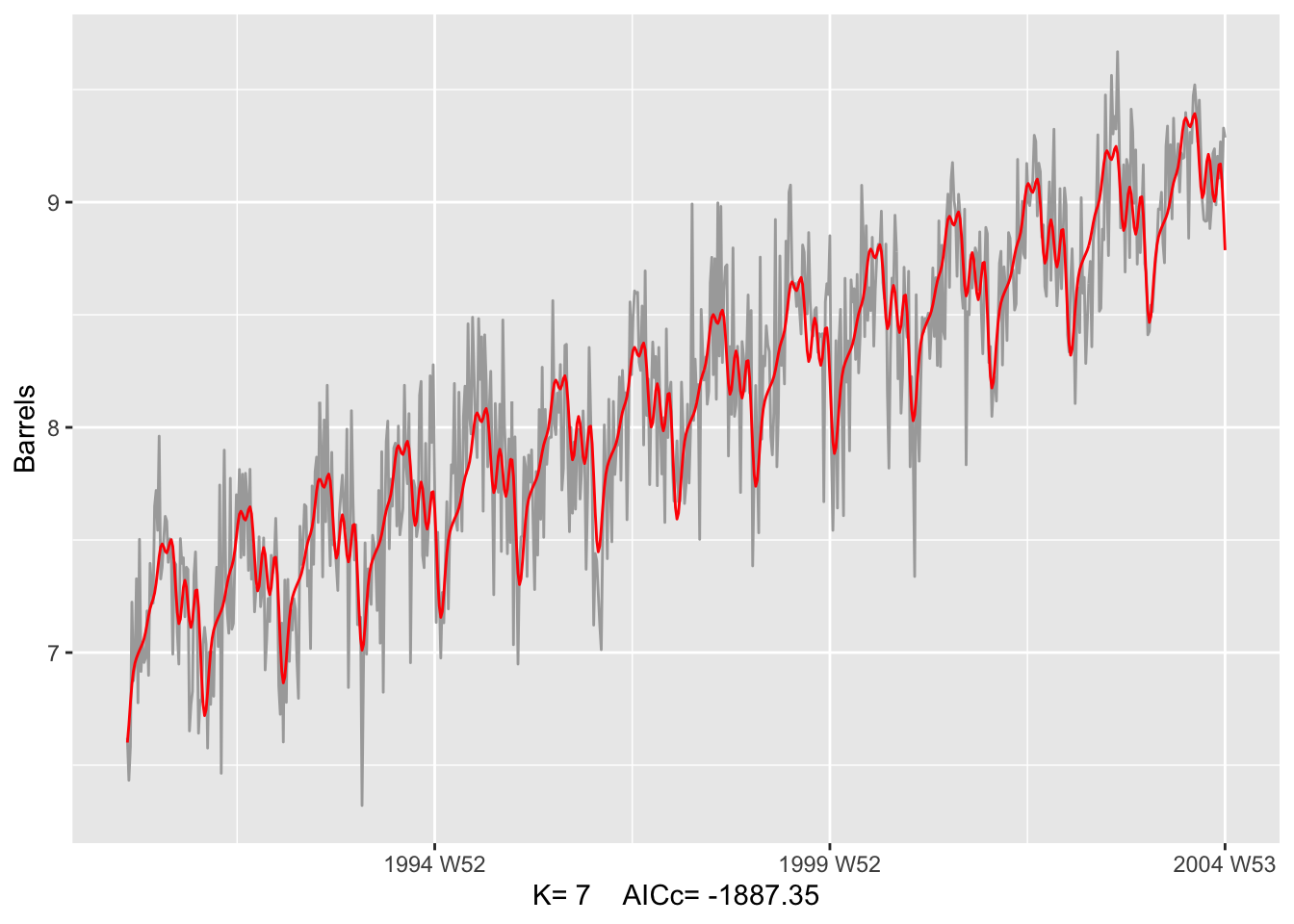
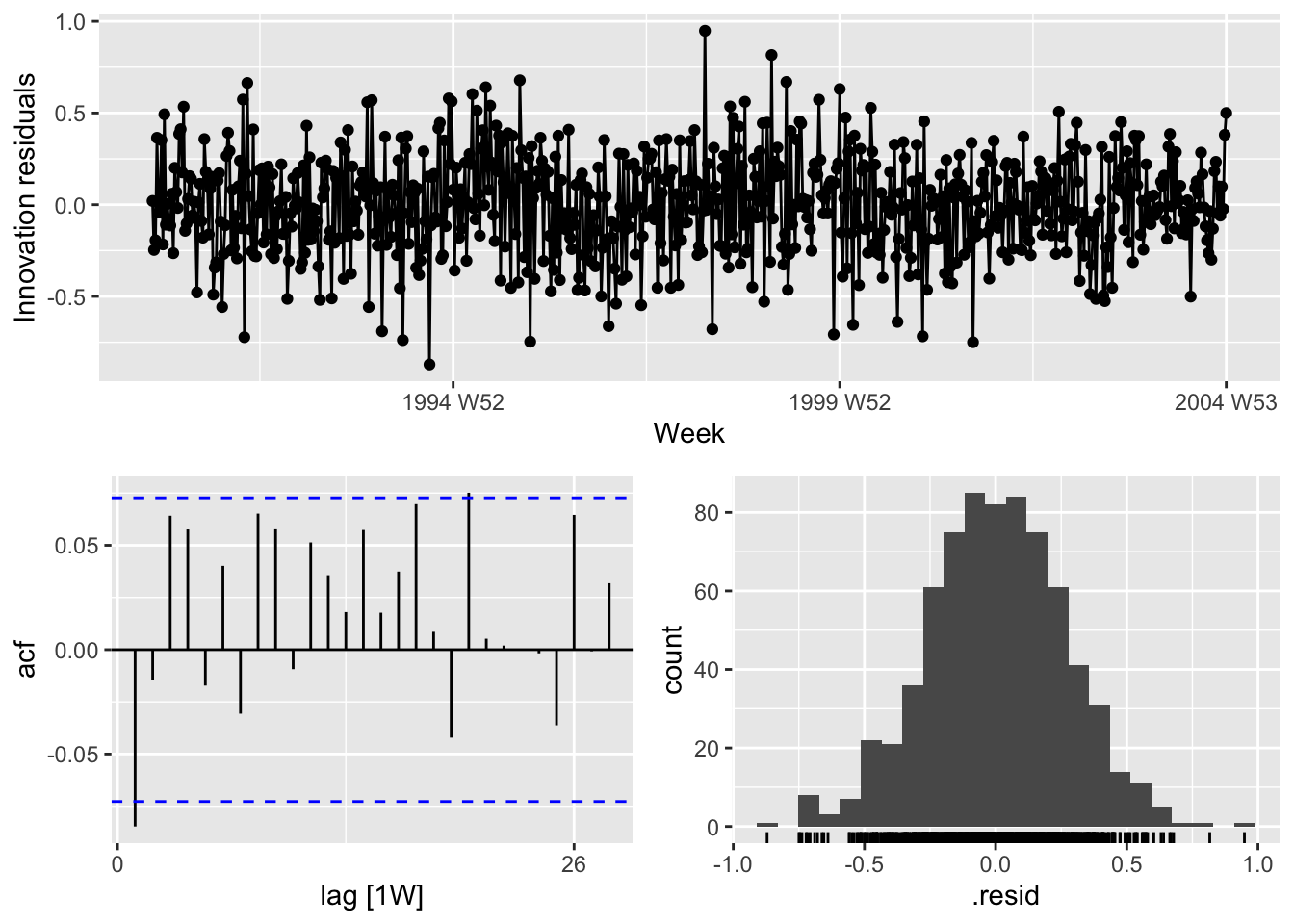
## # A tibble: 1 × 3
## .model lb_stat lb_pvalue
## <chr> <dbl> <dbl>
## 1 TSLM(Barrels ~ trend() + fourier(K = i)) 5.23 0.0222# d.
us_gasoline |>
filter(year(Week) < 2006) |>
autoplot(Barrels) +
autolayer(fits[[K]] |>
forecast(h = 52), color='red', level=NULL)## Warning: There was 1 warning in `mutate()`.
## ℹ In argument: `TSLM(Barrels ~ trend() + fourier(K = i)) = (function (object, ...) ...`.
## Caused by warning:
## ! prediction from a rank-deficient fit may be misleading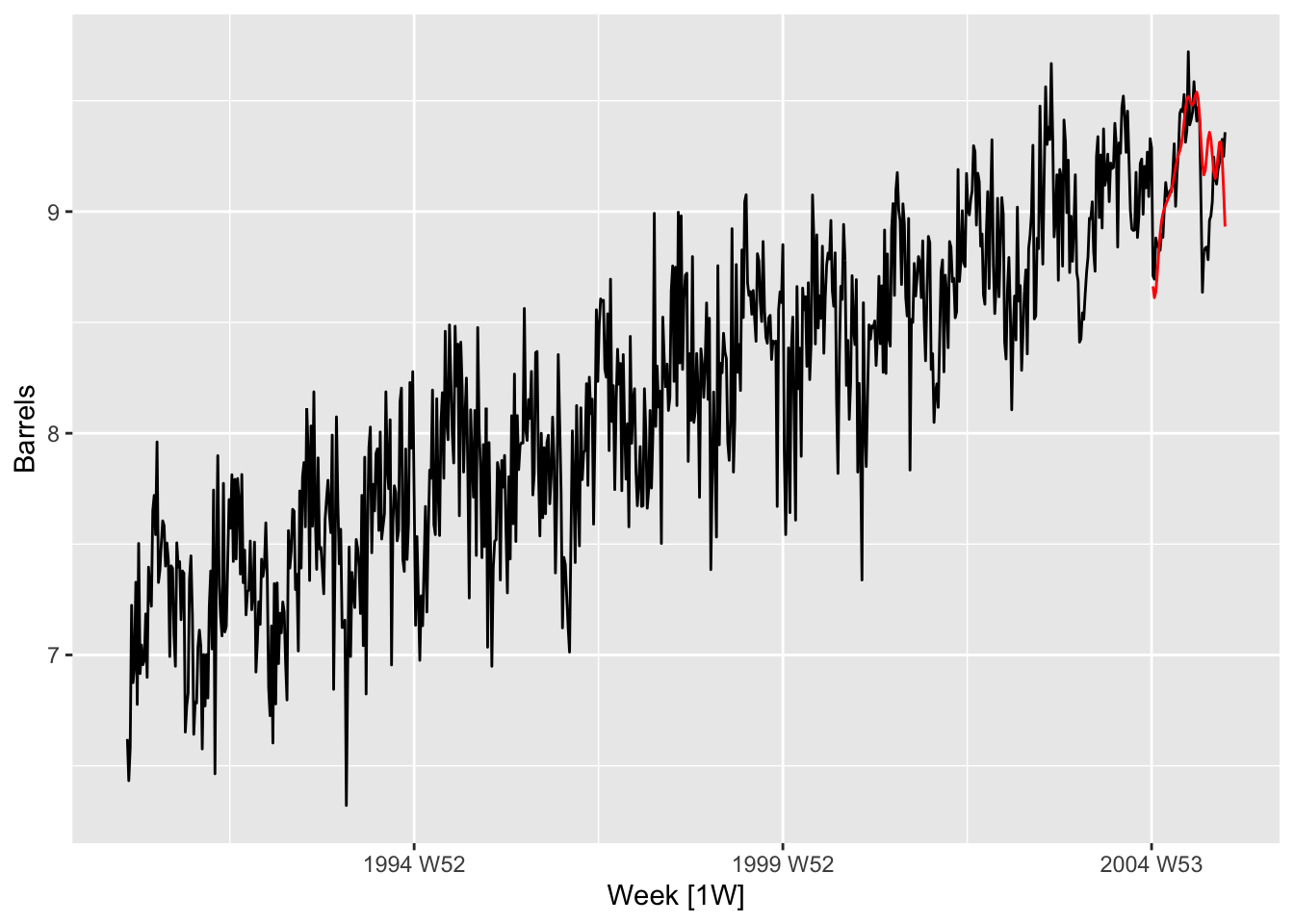 6.
6.
# a.
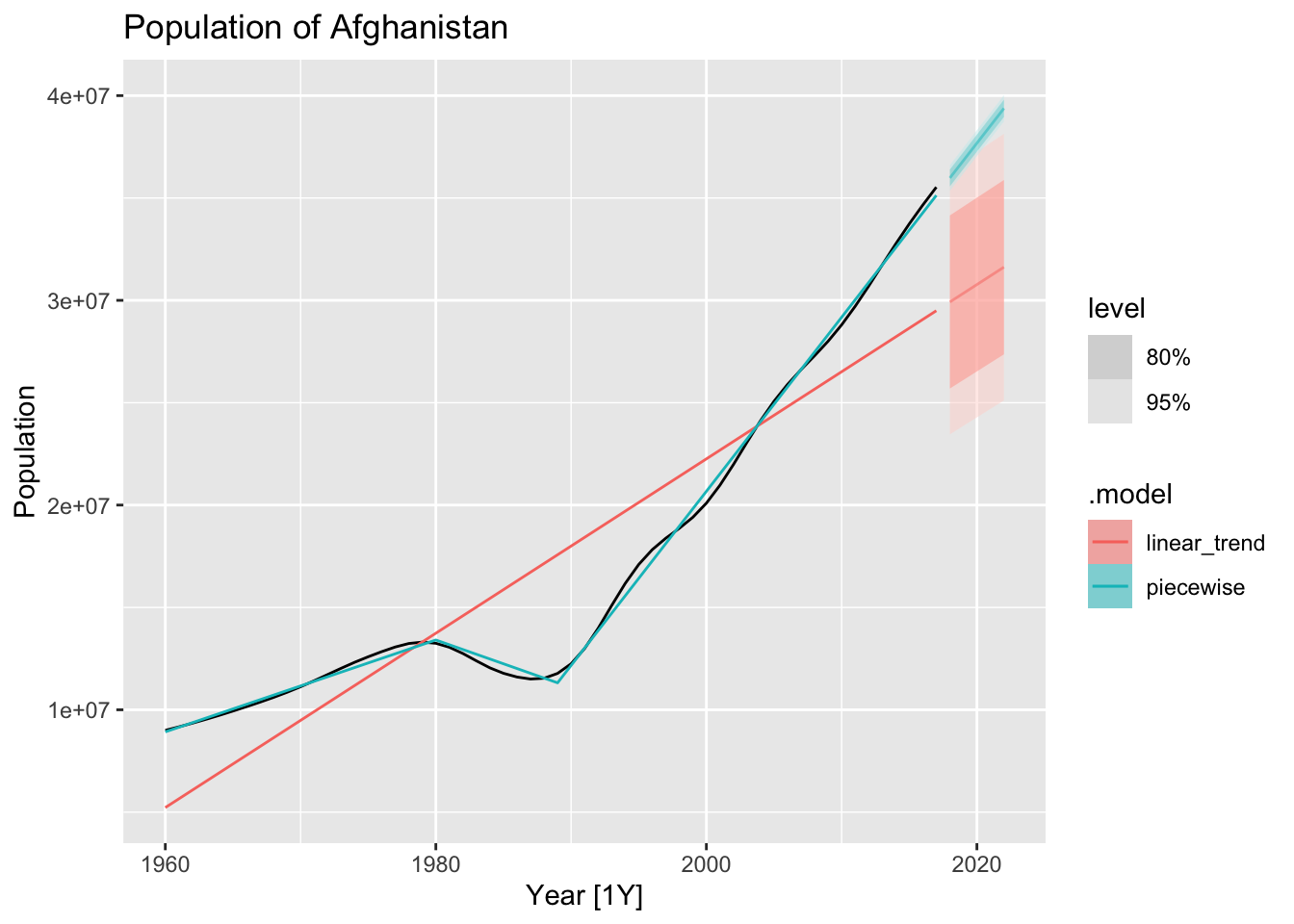
auf <- global_economy |>
filter(Country == 'Afghanistan')
auf |> autoplot(Population) +
labs(title = 'Population of Afghanistan')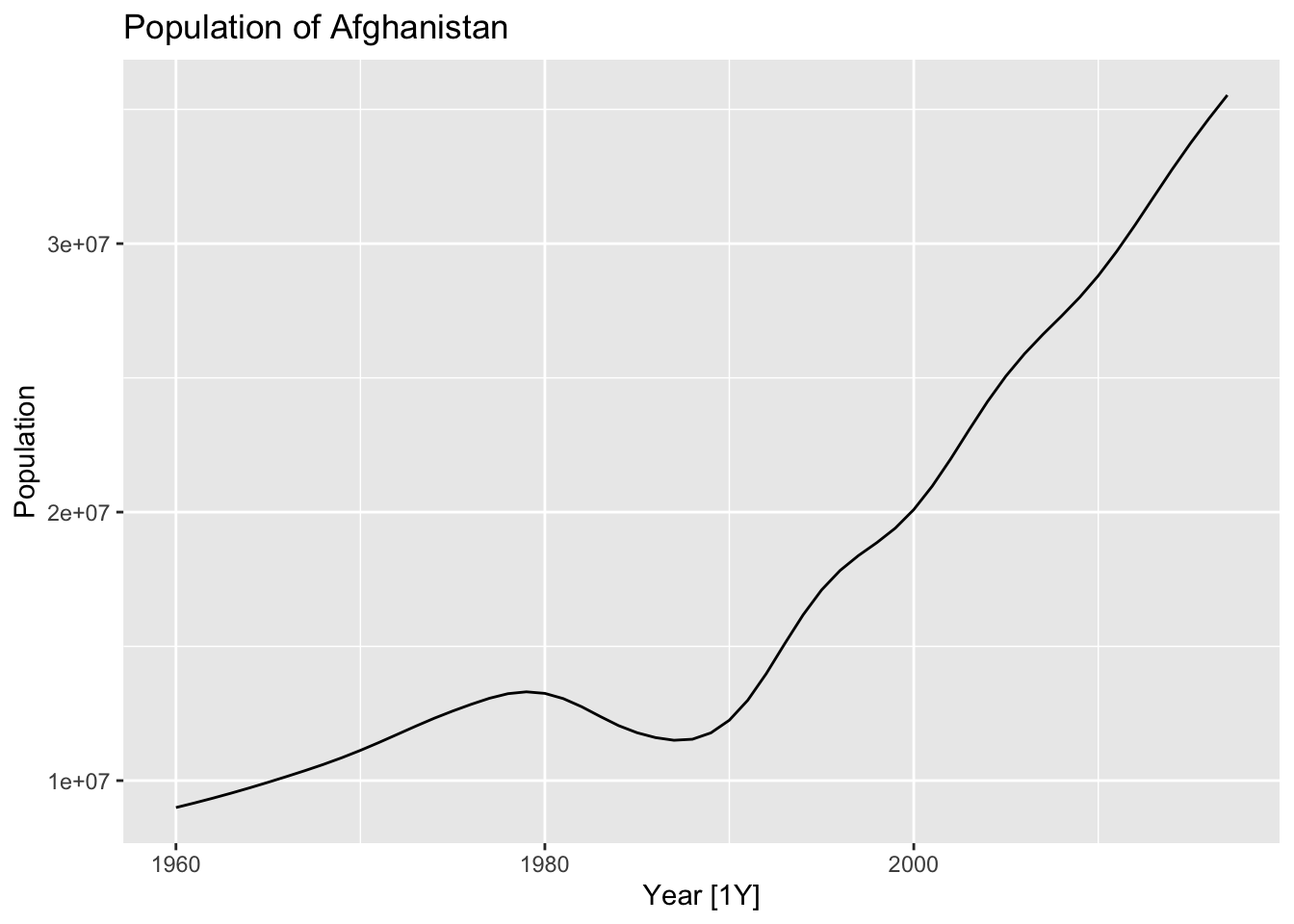
# b.
fit_trends <- auf |>
model(
linear_trend = TSLM(Population ~ trend()),
piecewise = TSLM(Population ~ trend(knots = c(1980, 1989)))
)
auf |>
autoplot(Population) +
geom_line(data = fitted(fit_trends),
aes(y = .fitted, color = .model)) +
labs(title = 'Population of Afghanistan')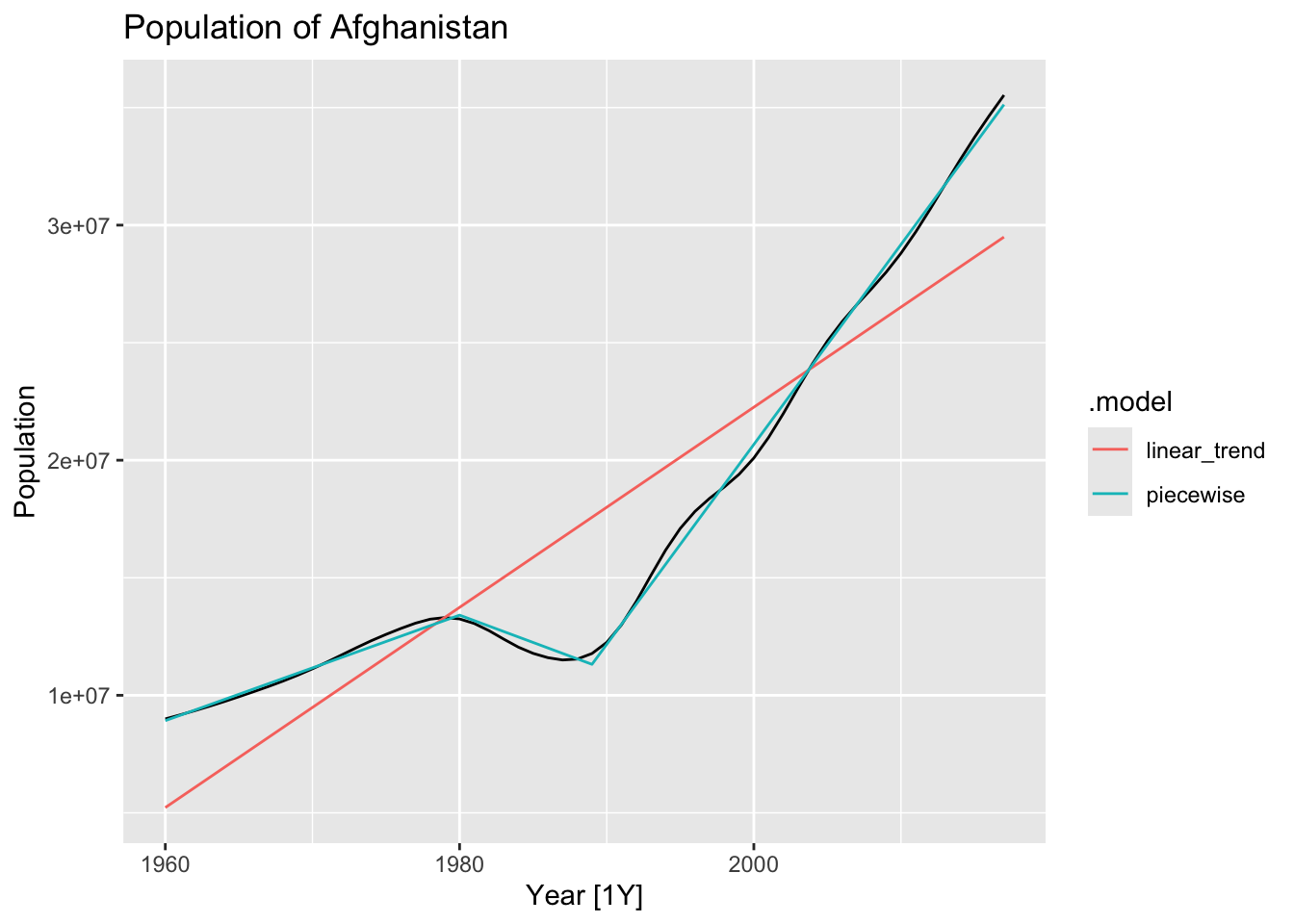
fc_trends <- fit_trends |> forecast(h = 5)
auf |>
autoplot(Population) +
geom_line(data = fitted(fit_trends),
aes(y = .fitted, color = .model)) +
autolayer(fc_trends, alpha = 0.5) +
labs(title = 'Population of Afghanistan')